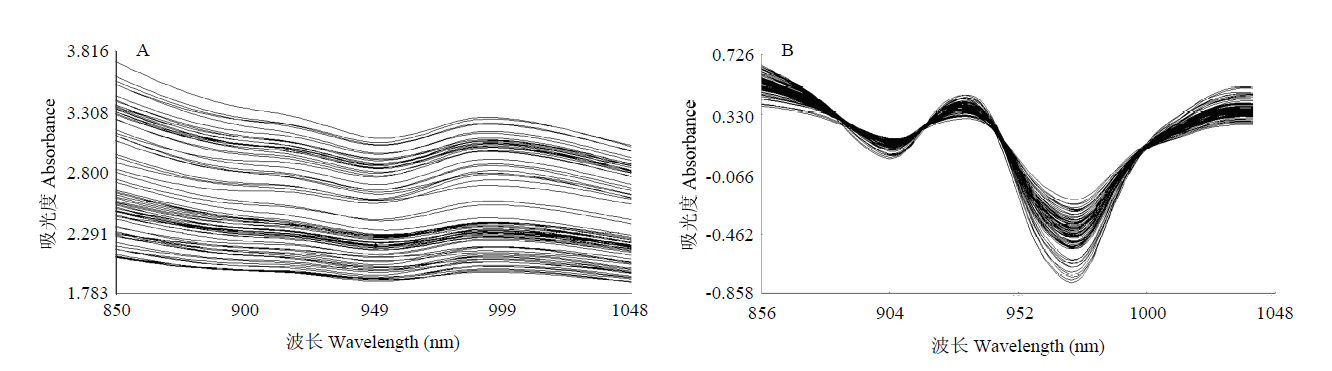
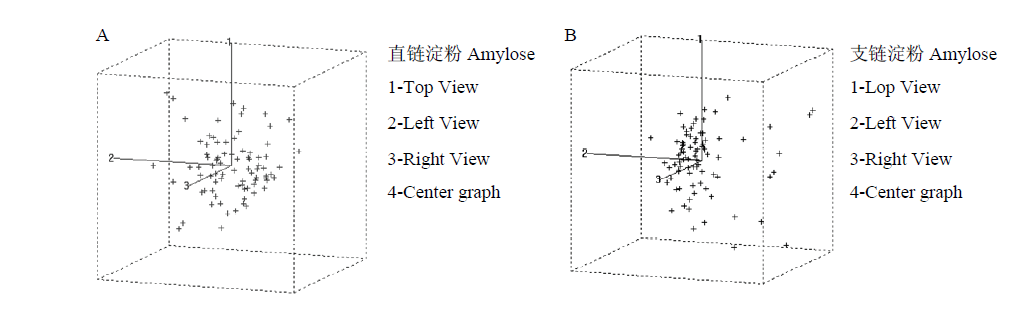
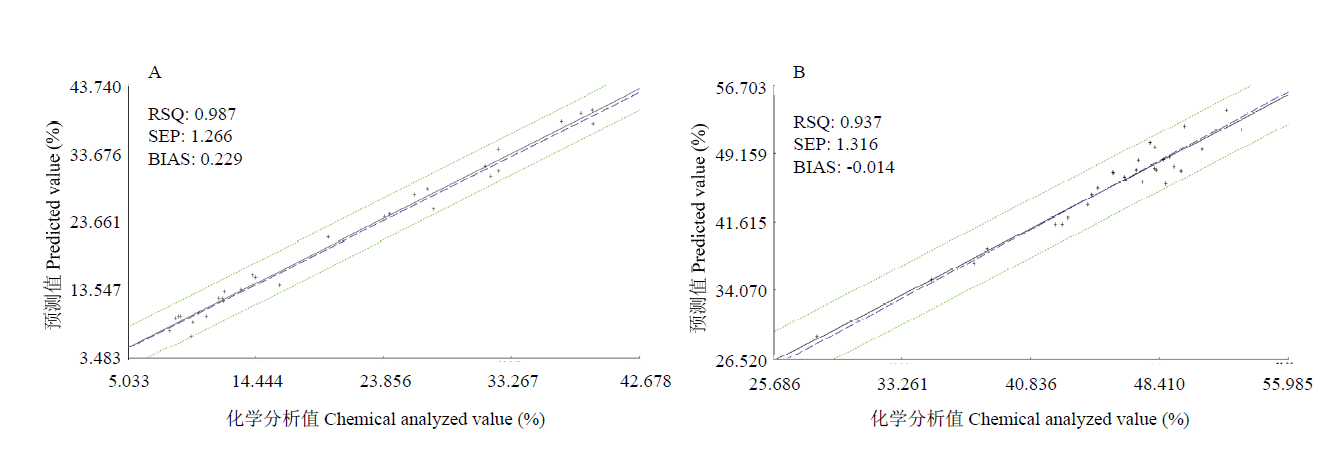
| [1] |
焦少杰, 王黎明, 姜艳喜, 严洪冬, 苏德峰, 孙广全. 高粱与固态白酒关系的研究综述. 酿酒, 2015, 42(1): 13-16.
|
|
JIAO S J, WANG L M, JIANG Y X, YAN H D, SU D F, SUN G Q. A review of the research on the relationship between sorghum and solid liquor. Wine Making, 2015, 42(1): 13-16. (in Chinese)
|
| [2] |
OMAR J, SLOWIKOWSKI B, BOIX A. Chemometric approach for discriminating tobacco trademarks by near infrared spectroscopy. Forensic Science International, 2019, 294: 15-20.
doi: 10.1016/j.forsciint.2018.10.016
|
| [3] |
CHEN H, TAN C, LIN Z, LI H J. Quantifying several adulterants of Noto ginseng powder by near-infrared spectroscopy and multivariate calibration. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, 2018, 211: 280-286.
doi: 10.1016/j.saa.2018.12.003
|
| [4] |
SIRSOMBOON P, POSOM J. On-line measurement of activation energy of ground bamboo using near infrared spectroscopy. Renewable Energy, 2019, 133: 480-488.
doi: 10.1016/j.renene.2018.10.051
|
| [5] |
陈雪萍, 刘世尧, 尹能文, 荆凌云, 魏丽娟, 林呐, 肖阳, 徐新福, 李加纳, 刘列钊. 甘蓝型油菜茎秆纤维组分含量和木质素单体G/S近红外模型构建. 中国农业科学, 2018, 51(4): 688-698.
|
|
CHEN X P, LIU S Y, YIN N W, JING L Y, WEI L J, LIN N, XIAO Y, XU X F, LI J N, LIU L Z. Construction of NIR model of fiber component content and lignin monomer G/S in Brassica napus stalk. Scientia Agricultura Sinica, 2018, 51(4): 688-698. (in Chinese)
|
| [6] |
TKACHUK R. Oil and protein analysis of whole rapeseed kernels by near infrared reflectance spectroscopy. Journal of the American Oil Chemists’ Society, 1981, 58(8): 819-822.
doi: 10.1007/BF02665588
|
| [7] |
PANFORD J A, WILLIAMS P C, DEMAN J M. Analysis of oilseeds for protein, oil, fiber and moisture by near-infrared reflectance spectroscopy. Journal of the American Oil Chemists’ Society, 1988, 65(10): 1627-1634.
doi: 10.1007/BF02912567
|
| [8] |
王翠秀, 曹建飞, 顾振飞, 徐明雪, 吴泉源. 基于近红外光谱大豆蛋白质、脂肪快速无损检测模型的优化构建. 大豆科学, 2019, 38(6): 968-976.
|
|
WANG C X, CAO J F, GU Z F, XU M X, WU Q Y. Optimized construction of a rapid non-destructive detection model for soybean protein and fat based on near-infrared spectroscopy. Soybean Science, 2019, 38(6): 968-976. (in Chinese)
|
| [9] |
ZHANG Y M, GUO W C. Moisture content detection of maize seed based on visible/near-infrared and near-infrared hyperspectral imaging technology. International Journal of Food Science and Technology. 2020, 55: 631-640.
doi: 10.1111/ijfs.v55.2
|
| [10] |
李佳佳, 洪慧龙, 万明月, 储丽, 赵敬会, 汪明华, 徐志鹏, 张阴, 黄志平, 张文明, 王晓波, 邱丽娟. 基于近红外光谱的大豆茎秆化学组分含量检测模型构建与应用. 中国农业科学, 2021, 54, 54(5): 887-900.
|
|
LI J J, HONG H L, WAN M Y, CHU L, ZHAO J H, WANG M H, XU Z P, ZHANG Y, HUANG Z P, ZHANG W M, WANG X B, QIU L J. Construction and application of soybean stem chemical composition detection model based on near infrared spectroscopy. Scientia Agricultura Sinica, 2021, 54, 54(5): 887-900. (in Chinese)
|
| [11] |
黄朝晖, 陆平, 杨楠, 孟宪军, 任贵兴. 近红外光谱法测定高粱原花青素含量. 食品科技, 2008(10): 207-210.
|
|
HUANG Z H, LU P, YANG N, MENG X J, REN G X. Determination of proanthocyanidins content of sorghum by near infrared spectroscopy. Food Science and Technology, 2008(10): 207-210. (in Chinese)
|
| [12] |
刘敏轩, 黄赟文, 韩建国. 高粱籽粒中多酚类物质的傅里叶变换近红外光谱分析. 分析化学, 2009, 37(9): 1275-1280.
|
|
LIU M X, HUANG Y W, HAN J G. Fourier transform near infrared spectroscopy analysis of polyphenols in sorghum grains. Chinese Journal of Analytical Chemistry, 2009, 37(9): 1275-1280. (in Chinese)
|
| [13] |
SIMEONE M L F, PARRELLA R A C, SCHAFFERT R E S, DAMASCENO C M B, LEAL M C B, PASQUINI C. Near infrared spectroscopy determination of sucrose, glucose and fructose in sweet sorghum juice. Microchemical Journal, 2017, 134: 125-130.
doi: 10.1016/j.microc.2017.05.020
|
| [14] |
纪楠. 大豆秸秆木质素和纤维素含量与近红外光谱相关性模型研究[D]. 哈尔滨: 东北农业大学, 2016.
|
|
JI N. Research on the correlation model between lignin and cellulose content of soybean straw and near infrared spectroscopy[D]. Harbin: Northeast Agricultural University, 2016. (in Chinese)
|
| [15] |
CELIO P. Near infrared spectroscopy: Fundamentals, practical aspects and analytical applications. Journal of the Brazilian Society, 2003, 4(1): 198-219.
|
| [16] |
GB/T15683-2008, 大米直链淀粉含量的测定. 北京: 中国标准出版社, 2008.
|
|
GB/T15683-2008, Determination of amylose content in rice. Beijing: China Standard Press, 2008. (in Chinese)
|
| [17] |
GARRIDOVARO A, GARCIAOLMO J, FEARN T. A note on Mahalanobis and related distance measures in WinISI and The Unscrambler. Journal of Near Infrared Spectroscopy, 2019, 27(4): 253-258.
doi: 10.1177/0967033519848296
|
| [18] |
BAI T C, WANG T, CHEN Y Q, MERCATORIS B. Comparison of near-infrared spectrum pretreatment methods for Jujube leaf moisture content detection in the sand and dust area of southern Xinjiang. Spectroscopy and Spectral Analysis, 2019, 39: 1323-1328.
|
| [19] |
郑震璇. 近红外光谱分析技术在饲料加工行业的应用. 福建农机, 2019, 40(1): 24-27.
|
|
ZHENG Z X. Application of near infrared spectroscopy analysis technology in feed processing industry. Fujian Agricultural Machinery, 2019, 40(1): 24-27. (in Chinese)
|
| [20] |
VAMADEVAN V, BERTOFT E. Structure-function relationships of starch components. Starch-Stärke, 2015, 67(1/2): 55-68.
doi: 10.1002/star.v67.1-2
|
| [21] |
LEE J H, YOU S, KWEON D K, CHUNG H J, LIM S T. Dissolution behaviors of waxy maize amylopectin in aqueous-DMSO solutions containing NaCl and CaCl2. Food Hydrocolloids, 2014, 35: 115-121.
doi: 10.1016/j.foodhyd.2013.05.003
|
| [22] |
BERTOFT E. Understanding starch structure: Recent progress. Agronomy 2017, 7: 1-29.
doi: 10.3390/agronomy7010001
|
| [23] |
郝勇. 近红外光谱微量分析方法研究[D]. 天津: 南开大学, 2009.
|
|
HAO Y. Research on near infrared spectroscopy microanalysis method[D]. Tianjin: Nankai University. 2009. (in Chinese)
|
| [24] |
梁晓燕, 吉海彦. 近红外光谱技术在农作物品质分析方面的应用. 中国农学通报, 2006, 22(1): 366-371.
|
|
LIANG X Y, JI H Y. Application of near infrared spectroscopy technology in crop quality analysis. Chinese Agricultural Science Bulletin, 2006, 22(1): 366-371. (in Chinese)
|
| [25] |
王家多, 周向阳, 金同铭, 胡祥娜, 钟娇娥, 吴启堂. 近红外光谱检测技术在农业和食品分析上的应用. 光谱学与光谱分析, 2004, 24(4): 447-450.
|
|
WANG J D, ZHOU X Y, JIN T M, HU X N, ZHONG J E, WU Q T. The application of near-infrared spectroscopy detection technology in agriculture and food analysis. Spectroscopy and Spectral Analysis, 2004, 24(4): 447-450. (in Chinese)
|
| [26] |
刘红梅, 肖正午, 申涛, 蒋鹏, 单双吕, 邹应兵. 稻米直链淀粉含量近红外检测模型的建立. 湖南农业大学学报, 2019, 45(2): 189-193.
|
|
LIU H M, XIAO Z W, SHEN T, JIANG P, SHAN S L, ZOU Y B. Establishment of near infrared detection Model of rice amylose content. Journal of Hunan Agricultural University, 2019, 45(2): 189-193. (in Chinese)
|
| [27] |
王勇生, 李洁, 王博, 张宇婷, 耿俊林. 基于近红外光谱技术评估高粱中粗蛋白质、水分含量的研究. 动物营养学报, 2020, 32(3): 1353-1361.
|
|
WANG Y S, LI J, WANG B, ZHANG Y T, GENG J L. Research on the evaluation of crude protein and moisture content in sorghum based on near-infrared spectroscopy technology. Chinese Journal of Animal Nutrition, 2020, 32(3): 1353-1361. (in Chinese)
|
| [28] |
巫小建, 曾凡荣, 岳文浩, 汪军妹. 大麦籽粒总淀粉含量近红外快速无损检测模型的构建. 浙江农业科学, 2021, 62(1): 40-41.
|
|
WU X J, ZENG F R, YUE W H, WANG J M. Construction of a near-infrared rapid non-destructive detection model for the total starch content of barley grains. Zhejiang Agricultural Sciences, 2021, 62(1): 40-41. (in Chinese)
|
| [29] |
韩浩楠, 王美娟, 赵训超, 鲁鑫, 周志强, 李明顺, 张德贵, 郝传芳, 翁剑峰, 雍红军, 李新海. 玉米粉淀粉含量近红外模型建立与优化. 玉米科学, 2020, 28(6): 81-87.
|
|
HAN H N, WANG M J, ZHAO X C, LU X, ZHOU Z Q, LI M S, ZHANG D G, HAO C F, WENG J F, YONG H J, LI X H. Establishment and optimization of near-infrared model of corn flour starch content. Maize Science, 2020, 28(6): 81-87. (in Chinese)
|
| [30] |
KIM G, HONG S J, LEE A Y, LEE Y E, LM S. Moisture content measurement of broadleaf litters using near-infrared spectroscopy technique. Remote Sensing, 2017, 9(12): 1212.
doi: 10.3390/rs9121212
|
| [31] |
CHEN J M, LI M L, PAN T, PANG L W, YAO L J, ZHANG J. Rapid and non-destructive for the identification of multi-grain rice seeds with near-infrared spectroscopy. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, 2019, 219(5): 179-185.
doi: 10.1016/j.saa.2019.03.105
|







 ),陈松树,李魁印,李鲁华,徐如宏,安畅,熊富敏,张燕,董俐利,任明见(
),陈松树,李魁印,李鲁华,徐如宏,安畅,熊富敏,张燕,董俐利,任明见(