






中国农业科学 ›› 2020, Vol. 53 ›› Issue (21): 4449-4459.doi: 10.3864/j.issn.0578-1752.2020.21.013
钟亮( ),郭熙(),国佳欣,韩逸,朱青,熊杏
),郭熙(),国佳欣,韩逸,朱青,熊杏
收稿日期:2020-02-22
接受日期:2020-03-18
出版日期:2020-11-01
发布日期:2020-11-11
通讯作者:
郭熙
作者简介:钟亮,E-mail:基金资助:
ZHONG Liang(),GUO Xi(),GUO JiaXin,HAN Yi,ZHU Qing,XIONG Xing
Received:2020-02-22
Accepted:2020-03-18
Online:2020-11-01
Published:2020-11-11
Contact:
Xi GUO
摘要:
【目的】 寻找红壤地区不同土壤质地类型的Vis-NIR光谱反射规律,通过光谱对土壤质地类别进行快速、准确的预测。【方法】 以江西省奉新县北部为研究区,245个土壤样本为研究对象,在国际制土壤质地4组和12级两种分类标准下,首先分析不同土壤质地类型的光谱反射率,然后采用9种数学变换方法和5种机器学习算法相互组合的数据挖掘模型,进行土壤质地的分类研究,最后对建模准确度最高的混淆矩阵和预测结果三角坐标分布图进行分析。【结果】 (1)不同土壤质地之间的光谱反射率存在较多的交叉重叠现象,土壤质地与光谱反射率之间的规律较为复杂;(2)分数阶导数变换是整数阶导数的扩展,有助于土壤质地的分类,但原始光谱数据具有更加丰富的特征信息,更适合进行土壤质地分类建模;(3)在对非均衡数据集建模时,集成学习方法和神经网络方法都是不错的选择;(4)较难通过模型去区分土壤质地分界线附近的类别,其中在4组分类标准下最容易被预测错误成黏壤土组,在12级分类标准下最容易被预测错误成黏壤土和壤质黏土这两种土壤质地类型;(5)在4组分类标准中,进行归一化处理和MLP模型组合取得了0.68的最高预测准确度,其中黏壤土组的预测准确度能达到0.84;再细分到12级分类后,分类效果最佳的组合来自于原始数据和MLP模型,其中壤质黏土分类准确度达到了0.89。【结论】 本研究结果可为南方红壤地区通过高光谱数据进行土壤质地分类提供参考依据。
钟亮,郭熙,国佳欣,韩逸,朱青,熊杏. 基于数据挖掘技术的高光谱土壤质地分类研究[J]. 中国农业科学, 2020, 53(21): 4449-4459.
ZHONG Liang,GUO Xi,GUO JiaXin,HAN Yi,ZHU Qing,XIONG Xing. Soil Texture Classification of Hyperspectral Based on Data Mining Technology[J]. Scientia Agricultura Sinica, 2020, 53(21): 4449-4459.

图1
研究区采样点分布示意图"
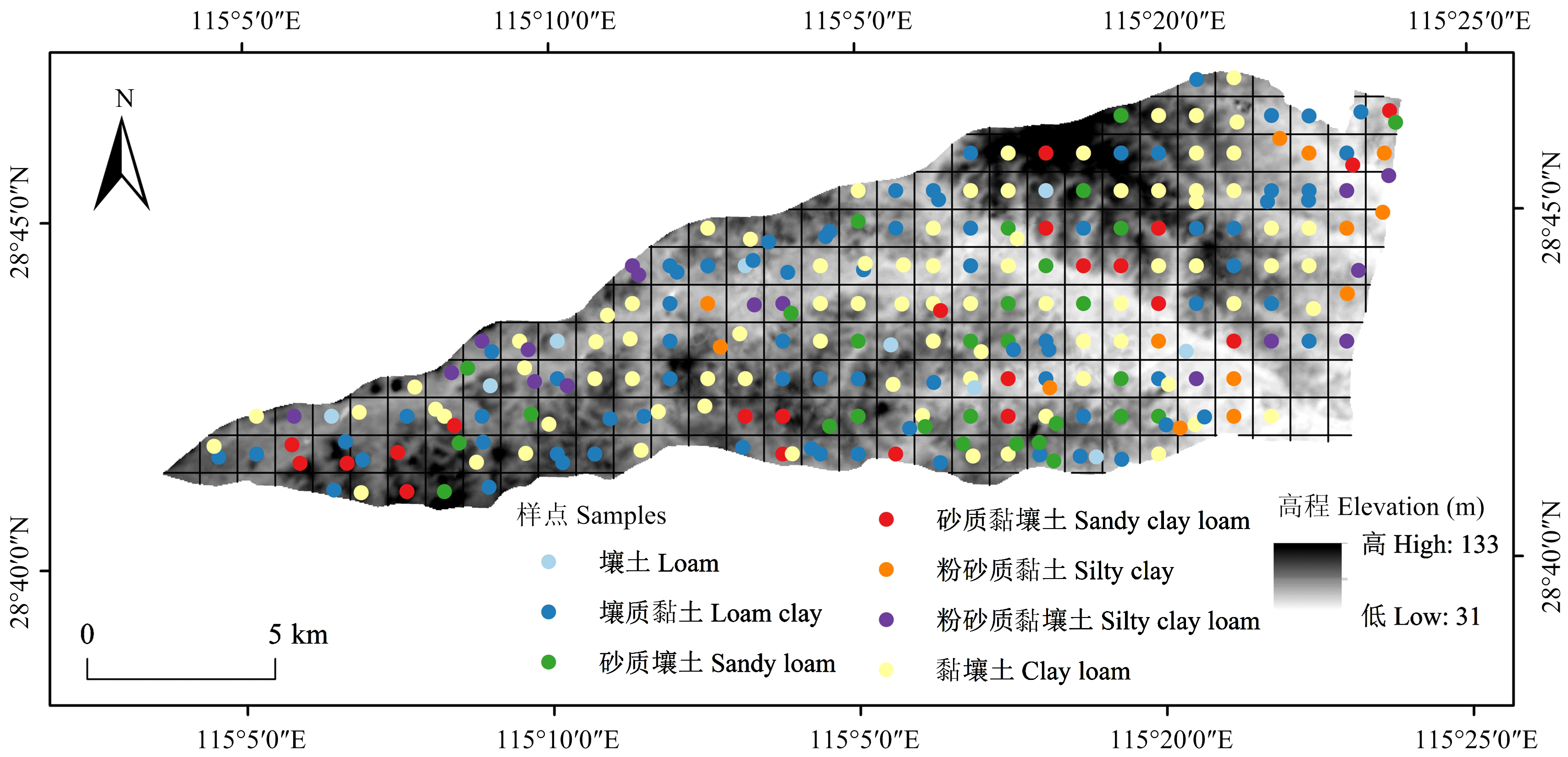
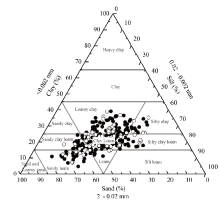
图2
国际制土壤质地分类和土壤样本示意图"
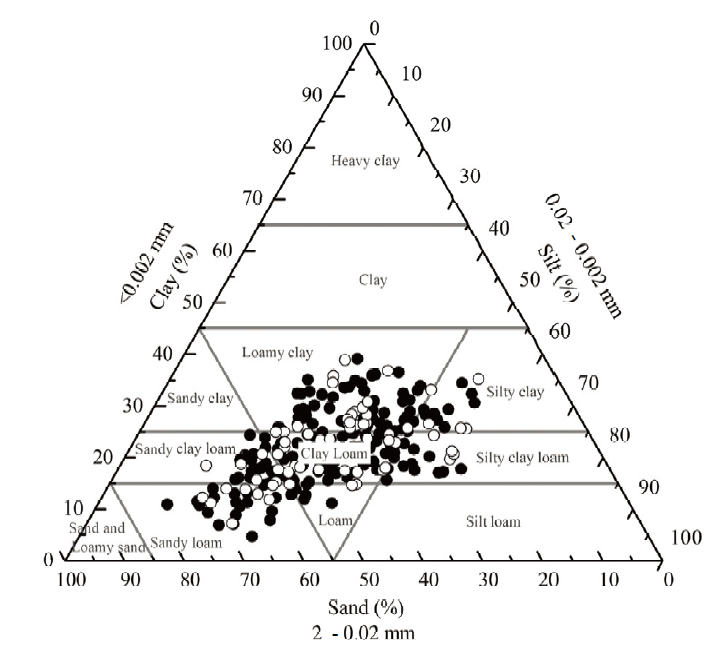
表1
土壤质地统计结果"
| 4组分类 4 groups of classifications | 12级分类 12 levels of classifications | 全部样本 All samples | 训练样本 Training samples | 验证样本 Validation samples |
|---|---|---|---|---|
| 壤土组 Loam group | 砂质壤土 Sandy loam | 29 | 21 | 8 |
| 壤土 Loam | 9 | 6 | 3 | |
| 黏壤土组 Clay loam group | 砂质黏壤土 Sandy clay loam | 22 | 16 | 6 |
| 黏壤土 Clay loam | 81 | 60 | 21 | |
| 粉砂质黏壤土 Silty clay loam | 16 | 12 | 4 | |
| 黏土组 Clay group | 粉砂质黏土 Silty clay | 13 | 9 | 4 |
| 壤质黏土 Loamy clay | 75 | 56 | 19 | |
| 合计 Total | 245 | 180 | 65 | |
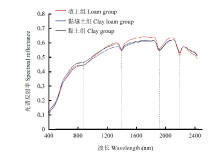
图3
4组分类土壤质地反射光谱曲线"
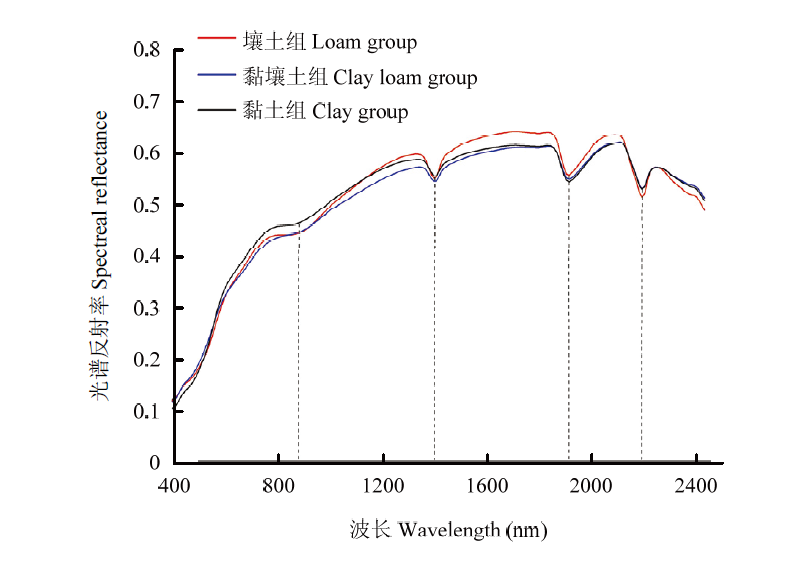
图4
12级分类土壤质地反射光谱曲线"
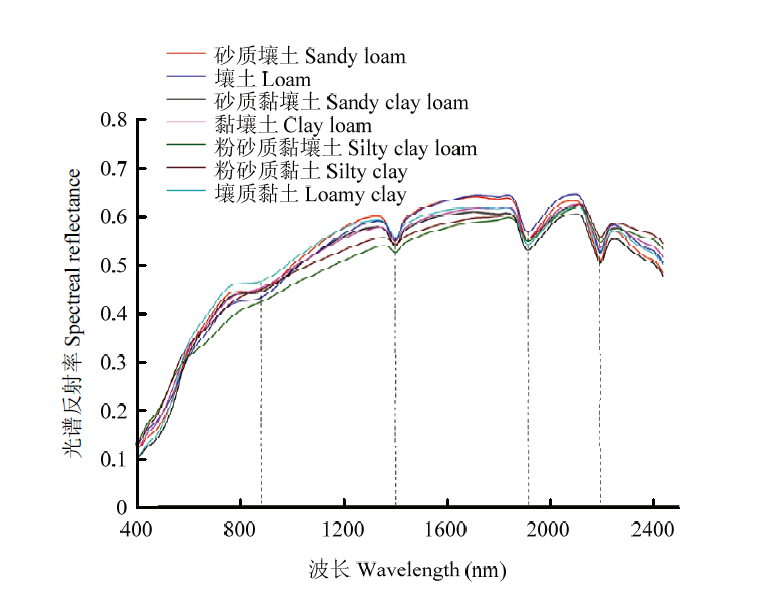
表2
9种数据处理和5种模型进行土壤质地4组分类的准确度比较"
| Method | SVM | DT | AdaBoost | RF | MLP |
|---|---|---|---|---|---|
| R | 0.63 | 0.60 | 0.63 | 0.60 | 0.65 |
| Normalization | 0.57 | 0.54 | 0.63 | 0.60 | 0.68 |
| Standardization | 0.60 | 0.55 | 0.63 | 0.60 | 0.62 |
| FOD(0.5) | 0.65 | 0.52 | 0.55 | 0.58 | 0.66 |
| FOD(1) | 0.52 | 0.55 | 0.62 | 0.55 | 0.63 |
| FOD(1.5) | 0.57 | 0.57 | 0.60 | 0.65 | 0.65 |
| FOD(2) | 0.54 | 0.57 | 0.60 | 0.60 | 0.63 |
| ILR | 0.51 | 0.58 | 0.63 | 0.63 | 0.63 |
| LDR | 0.52 | 0.58 | 0.58 | 0.55 | 0.62 |
表3
归一化处理和MLP模型混淆矩阵"
| 4组分类 4 groups of classifications | 壤土组 Loam group | 黏壤土组 Clay loam group | 黏土组 Clay group | 合计 Total |
|---|---|---|---|---|
| 壤土组 Loam group | 4 | 7 | 0 | 11 |
| 黏壤土组 Clay loam group | 1 | 26 | 4 | 31 |
| 黏土组 Clay group | 0 | 9 | 14 | 23 |
| 合计 Total | 5 | 42 | 18 | 65 |

图5
归一化处理和MLP模型预测结果分布图"
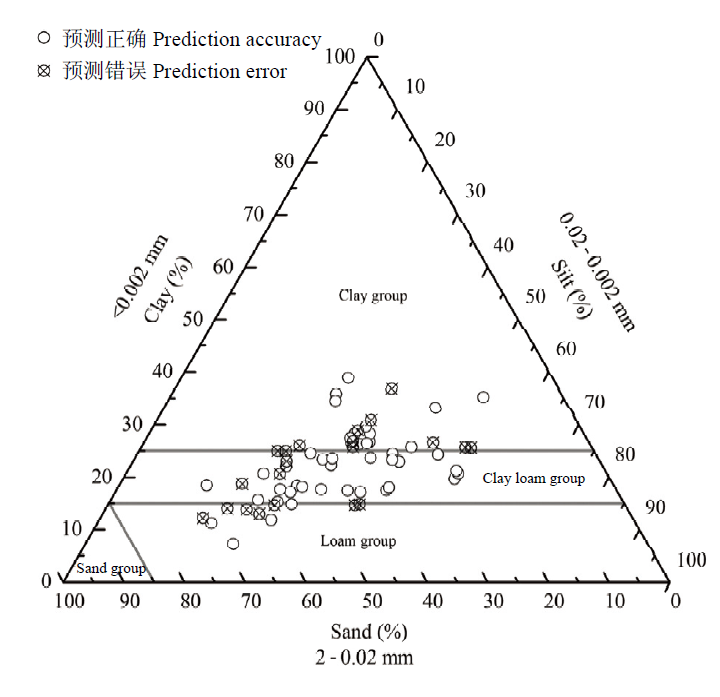
表4
9种数据处理和5种模型进行土壤质地12级分类的准确度比较"
| Method | SVM | DT | AdaBoost | RF | MLP |
|---|---|---|---|---|---|
| R | 0.48 | 0.46 | 0.52 | 0.51 | 0.55 |
| Normalization | 0.49 | 0.48 | 0.49 | 0.51 | 0.52 |
| Standardization | 0.46 | 0.48 | 0.51 | 0.51 | 0.52 |
| FOD(0.5) | 0.48 | 0.46 | 0.43 | 0.42 | 0.51 |
| FOD(1) | 0.40 | 0.42 | 0.48 | 0.46 | 0.49 |
| FOD(1.5) | 0.43 | 0.49 | 0.49 | 0.49 | 0.51 |
| FOD(2) | 0.42 | 0.42 | 0.46 | 0.48 | 0.49 |
| ILR | 0.45 | 0.49 | 0.51 | 0.46 | 0.49 |
| LDR | 0.40 | 0.46 | 0.49 | 0.48 | 0.49 |
表5
原始数据和MLP模型混淆矩阵"
| 12级分类 12 levels of classifications | 砂质壤土 Sandy loam | 壤土 Loam | 砂质黏壤土 Sandy clay loam | 黏壤土 Clay loam | 粉砂质黏壤土 Silty clay loam | 粉砂质黏土 Silty clay | 壤质黏土 Loamy clay | 合计 Total |
|---|---|---|---|---|---|---|---|---|
| 砂质壤土 Sandy loam | 3 | 0 | 0 | 3 | 0 | 1 | 1 | 8 |
| 壤土 Loam | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 3 |
| 砂质黏壤土 Sandy clay loam | 0 | 0 | 1 | 2 | 0 | 1 | 2 | 6 |
| 黏壤土 Clay loam | 1 | 0 | 0 | 14 | 0 | 3 | 3 | 21 |
| 粉砂质黏壤土 Silty clay loam | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 4 |
| 粉砂质黏土 Silty clay | 0 | 0 | 0 | 2 | 0 | 1 | 1 | 4 |
| 壤质黏土 Loamy clay | 0 | 0 | 0 | 2 | 0 | 0 | 17 | 19 |
| 合计 Total | 5 | 0 | 1 | 29 | 0 | 6 | 24 | 65 |
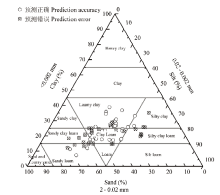
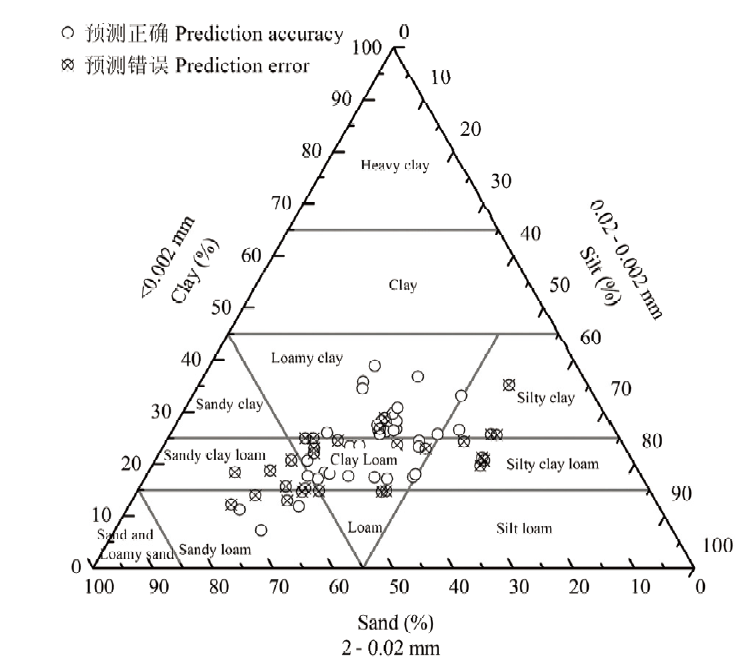
图6
原始数据和MLP模型预测结果分布图"
| [1] | GREVE M H, KHEIR R B, GREVE M B, BØCHER P K. Quantifying the ability of environmental parameters to predict soil texture fractions using regression-tree model with GIS and LIDAR data: The case study of Denmark. Ecological Indicators, 2012,18:1-10. |
| [2] | SHAHRIARI M, DELBARI M, AFRASIAB P, PAHLAVAN-Rad M R. Predicting regional spatial distribution of soil texture in floodplains using remote sensing data: A case of southeastern Iran. Catena, 2019,182:104149. |
| [3] | 吴克宁, 赵瑞. 土壤质地分类及其在我国应用探讨. 土壤学报, 2019,56(1):227-241. |
| WU K N, ZHAO R. Soil texture classification and its application in China. Acta Pedologica Sinica, 2019,56(1):227-241. (in Chinese) | |
| [4] | 张娜, 张栋良, 李立新, 屈忠义. 基于高光谱的区域土壤质地预测模型建立与评价——以河套灌区解放闸灌域为例. 干旱区资源与环境, 2014,28(5):67-72. |
| ZHANG N, ZHANG D L, LI L X, QU Z Y. Establishment and evaluation of model for predicting soil texture based on hyperspectral data—Case study of Jiefangzha irrigation area in Hetao irrigation district. Journal of Arid Land Resources and Environment, 2014,28(5):67-72. (in Chinese) | |
| [5] | 乔天, 吕成文, 肖文凭, 吕凯, 水宏伟. 基于遗传算法的土壤质地高光谱预测模型研究. 土壤通报, 2018,49(4):773-778. |
| QIAO T, LÜ C W, XIAO W P, LÜ K, SHUI H W. Hyperspectral prediction modeling of soil texture based on genetic algorithm. Chinese Journal of Soil Science, 2018,49(4):773-778. (in Chinese) | |
| [6] | 于雷, 洪永胜, 周勇, 朱强, 徐良, 李冀云, 聂艳. 高光谱估算土壤有机质含量的波长变量筛选方法. 农业工程学报, 2016,32(13):95-102. |
| YU L, HONG Y S, ZHOU Y, ZHU Q, XU L, LI J Y, NIE Y. Wavelength variable selection methods for estimation of soil organic matter content using hyperspectral technique. Transactions of the Chinese Society of Agricultural Engineering, 2016,32(13):95-102. (in Chinese) | |
| [7] | 史舟, 王乾龙, 彭杰, 纪文君, 刘焕军, 李曦. 中国主要土壤高光谱反射特性分类与有机质光谱预测模型. 中国科学:地球科学, 2014,44(5):978-988. |
| SHI Z, WANG Q L, PENG J, JI W J, LIU H J, LI X. Classification of hyperspectral reflectance characteristics and prediction model of organic matter spectra of main soils in China. Scientia Sinica (Terrae), 2014,44(5):978-988. (in Chinese) | |
| [8] | MÜLLER B BERNHARDT M, JACKISCH C, SCHULZ K. Estimating spatially distributed soil texture using time series of thermal remote sensing & ndash: A case study in central Europe. Hydrology and Earth System Sciences, 2016,20(9):3765-3775. |
| [9] | SAYAO V M, DEMATTÊJÉA M. Soil texture and organic carbon mapping using surface temperature and reflectance spectra in Southeast Brazil. Geoderma Regional, 2018,14:e174. |
| [10] | ZHAI Y S, THOMASSON J A, BOGGESS J E, SUI R X. Soil texture classification with artificial neural networks operating on remote sensing data. Computers and Electronics in Agriculture, 2006,54(2):53-68. |
| [11] | ZHAO Z Y, CHOW T L, REES H W, YANG Q, XING Z S, MENG F R. Predict soil texture distributions using an artificial neural network model. Computers & Electronics in Agriculture, 2009,65(1):36-48. |
| [12] | CHUNG S O, CHO K H, KONG J W, JUNG K Y. Soil Texture classification algorithm using RGB characteristics of soil images. IFAC Proceedings Volumes, 2010,43(26):34-38. |
| [13] | BARMAN U, CHOUDHURY R D. Soil texture classification using multi class support vector machine. Information Processing in Agriculture, 2020,7(2):318-332. |
| [14] | WU W, LI A D, HE X H, MA R, LIU H B, LÜ J K. A comparison of support vector machines, artificial neural network and classification tree for identifying soil texture classes in southwest China. Computers and Electronics in Agriculture, 2018,144:86-93. |
| [15] | ADHIKARI K, KHEIR R B, GREVE M B, BØCHER P K, MALONE B P, MINASNY B, MCBRATNEY A B, GREVE M H. High-resolution 3-D mapping of soil texture in denmark. Soil Science Society of America Journal, 2013,77(3):860-876. |
| [16] | LIE M, GLASER B, HUWE B. Uncertainty in the spatial prediction of soil texture. Geoderma, 2012,170:70-79. |
| [17] | 孙艳俊, 张甘霖, 杨金玲, 赵玉国. 基于人工神经网络的土壤颗粒组成制图. 土壤, 2012,44(2):312-318. |
| SUN Y J, ZHANG G L, YANG J L, ZHAO Y G. Mapping of soil particle composition based on artificial neural network. Soils, 2012,44(2):312-318. (in Chinese) | |
| [18] | SILVA S H G, WEINDORF D C, PINTO L C, FARIA W M, JUNIOR F W A, GOMIDE L R, MELLO J M D, JUNIOR A L D P, SOUZA I A D, TEIXEIRA A F D S, GUILHERME L R G, CURI N. Soil texture prediction in tropical soils: A portable X-ray fluorescence spectrometry approach. Geoderma, 2020,362:114136. |
| [19] | BAO N S, LIU S J, ZHOU Y C. Predicting particle-size distribution using thermal infrared spectroscopy from reclaimed mine land in the semi-arid grassland of North China. Catena, 2019,183:104190. |
| [20] | PENG Y, KNADEL M, GISLUM RÉ, SCHELDE K, THOMSEN A, GREVE M H. Quantification of SOC and clay content using visible Near-Infrared Reflectance-Mid-Infrared reflectance spectroscopy with Jack-Knifing partial least squares regression. Soil Science, 2014: 179(7):325-332. |
| [21] | 王德彩, 蔚霖, 张俊辉, 杨红震, 黄家荣, 孙孝林. 基于正交信号校正的Vis-NIR光谱土壤质地预测. 河南农业大学学报, 2017(3):408-413. |
| WANG D C, WEI L, ZHANG J H, YANG H Z, HUANG J R, SUN X L. Prediction of soil texture using Vis-NIR spectra based on orthogonal signal correction. Journal of Henan Agricultural University, 2017(3):408-413. (in Chinese) | |
| [22] | 王德彩, 邬登巍, 赵明松, 张甘霖. 平原区土壤质地的反射光谱预测与地统计制图. 土壤通报, 2012,43(2):257-262. |
| WANG D C, WU D W, ZHAO M S, ZHANG G L. Prediction and mapping of soil texture of a plain area using reflectance spectra and geo-statistics. Chinese Journal of Soil Science, 2012,43(2):257-262. (in Chinese) | |
| [23] | 沈掌泉, 单英杰, 王珂. 田间行走式测定的红外光谱数据与土壤质地之间的相关性研究. 光谱学与光谱分析, 2009,29(6):1526-1530. |
| SHEN Z Q, DAN Y J, WANG K. Study on relationship between on-the-go near-infrared spectroscopy and soil texture. Spectroscopy and Spectral Analysis, 2009,29(6):1526-1530. (in Chinese) | |
| [24] | AMIRIAN-CHAKAN A MINASNY B, TAGHIZADEH-MEHRJARDI R, AKBARIFAZLI R, DARVISHPASAND Z, KHORDEHBIN S. Some practical aspects of predicting texture data in digital soil mapping. Soil and Tillage Research, 2019,194:104289. |
| [25] | LARK R M, BISHOP T F A. Cokriging particle size fractions of the soil. European Journal of Soil Science, 2007,58(3):763-774. |
| [26] | 曾庆猛, 孙宇瑞, 严红兵. 土壤质地分类的近红外光谱分析方法研究. 光谱学与光谱分析, 2009,29(7):1759-1763. |
| ZENG Q M, SUN Y R, YAN H B. NIR spectral analysis for soil textural classification. Spectroscopy and Spectral Analysis, 2009,29(7):1759-1763. (in Chinese) | |
| [27] | 胡晓艳, 宋海燕. 基于支持向量机和近红外光谱特性的土壤质地分类. 山西农业科学, 2017,45(10):1643-1645. |
| HU X Y, SONG H Y. Soil texture classification based on support vector machine and near infrared spectral characteristics. Journal of Shanxi Agricultural Sciences, 2017,45(10):1643-1645. (in Chinese) | |
| [28] | 白燕英, 魏占民, 刘全明, 郭桂莲, 刘霞. 基于高光谱的河套灌区农田表层土壤质地反演研究. 地理与地理信息科学, 2013,29(5):68-71. |
| BAI Y Y, WEI Z M, LIU Q M, GUO G L, LIU X. Surface soil texture of field inverted using hyper-spectrum in Hetao irrigation. Geography and Geo-Information Science, 2013,29(5):68-71. (in Chinese) | |
| [29] | SALAZAR D F U, DEMATT JÉA M, VICENTE L E, GUIMARAES C C B, SAYAO V M, CERRI C E P, PADILHA M C D C, MENDES W D S. Emissivity of agricultural soil attributes in southeastern Brazil via terrestrial and satellite sensors. Geoderma, 2020,361:114038. |
| [30] | 黄明祥, 程街亮, 王珂, 龚建华, 李洪义, 史舟. 海涂土壤高光谱特性及其砂粒含量预测研究. 土壤学报, 2009,46(5):932-937. |
| HUANG M X, CHENG J L, WANG K, GONG J H, LI H Y, SHI Z. Coastal soil hyperspectral characteristics and soil sand content prediction. Acta Pedologica Sinica, 2009,46(5):932-937. (in Chinese) | |
| [31] | 王德彩, 张俊辉. 基于Vis-NIR光谱的土壤质地BP神经网络预测. 天津农业科学, 2015,21(8):6-9. |
| WANG D C, ZHANG J H. Estimation of soil texture based on Vis-NIR spectroscopy and BP neural network. Tianjin Agricultural Sciences, 2015,21(8):6-9. (in Chinese) | |
| [32] | 李春蕾, 许端阳, 陈蜀江. 基于高光谱遥感的新疆北疆地区土壤砂粒含量反演研究. 干旱区地理, 2012,35(3):473-478. |
| LI C L, XU D Y, CHEN S J. Soil sand content retrieving of bare soil in north Xinjiang based on hyper-spectral remote sensing. Arid Land Geography, 2012,35(3):473-478. (in Chinese) | |
| [33] | TONG P J, DU Y P, ZHENG K Y, WU T, WANG J J. Improvement of NIR model by fractional order Savitzky-Golay derivation(FOSGD) coupled with wavelength selection. Chemometrics and Intelligent Laboratory Systems, 2015,143:40-48. |
| [34] | 王敬哲, 塔西甫拉提·特依拜, 丁建丽, 张东, 刘巍. 基于分数阶微分预处理高光谱数据的荒漠土壤有机碳含量估算. 农业工程学报, 2016,32(21):161-169. |
| WANG J Z, TASHPOLAT TIYIP, DING J L, ZHANG D, LIU W. Estimation of desert soil organic carbon content based on hyperspectral data preprocessing with fractional differential. Transactions of the Chinese Society of Agricultural Engineering, 2016,32(21):161-169. (in Chinese) | |
| [35] | XU Z, ZHAO X M, GUO X, GUO J X. Deep learning application for predicting soil organic matter content by Vis-NIR spectroscopy. Computational Intelligence and Neuroscience, 2019,2019:1-11. |
| [36] | 纪文君, 李曦, 李成学, 周银, 史舟. 基于全谱数据挖掘技术的土壤有机质高光谱预测建模研究. 光谱学与光谱分析, 2012(9):91-96. |
| JI W J, LI X, LI C X, ZHOU Y, SHI Z. Using different data mining algorithms to predict soil organic matter based on visible-near infrared spectroscopy. Spectroscopy and Spectral Analysis, 2012(9):91-96. (in Chinese) | |
| [37] | ESHEL G, LEVY G J, MINGELGRIN U, SINGER M J. Critical evaluation of the use of laser diffraction for particle-size distribution analysis. Soil Science Society of America Journal, 2004,68(3):736. |
| [38] | 杨金玲, 张甘霖, 李德成, 潘继花. 激光法与湿筛-吸管法测定土壤颗粒组成的转换及质地确定. 土壤学报, 2009(5):22-30. |
| YANG J L, ZHANG G L, LI D C, PAN J H. Relationships of soil particle size distribution between sieve-pipetie and laser diffraction methods. Acta Pedologica Sinica, 2009(5):22-30. (in Chinese) | |
| [39] | 李学林, 李福春, 陈国岩, 谢昌仁, 王金平, 李文静. 用沉降法和激光法测定土壤粒度的对比研究. 土壤, 2011(1):132-136. |
| LI X L, LI M C, CHEN G Y, XIE C R, WANG J P, LI W J. Comparative study on grain-size measured by laser diffraction and sedimentation techniques. Soils, 2011(1):132-136. (in Chinese) | |
| [40] | 史舟. 土壤地面高光谱遥感原理与方法. 北京: 科学出版社, 2014: 61-63. |
| SHI Z. Principle and Method of Hyperspectral Remote Sensing of Soil Surface. Beijing: Science Press, 2014: 61-63. (in Chinese) | |
| [41] | HU Y G, JIANG T, SHEN A G, LI W, WANG X, HU J. A background elimination method based on wavelet transform for Raman spectra. Chemometrics & Intelligent Laboratory Systems, 2007,85(1):94-101. |
| [42] | 马翠红, 刘立业. 基于小波分析的光谱数据处理. 冶金分析, 2012,32(1):34-37. |
| MA C H, LIU L Y. Spectral data processing based on wavelet analysis. Metallurgical Analysis(China), 2012,32(1):34-37. (in Chinese) | |
| [43] | BENKHETTOU N, CRUZ A M C B D, TORRES D F M. A fractional calculus on arbitrary time scales: Fractional differentiation and fractional integration. Signal Processing, 2015,107:230-237. |
| [44] | 丁世飞, 齐丙娟, 谭红艳. 支持向量机理论与算法研究综述. 电子科技大学学报, 2011,40(1):2-10. |
| DING S F, QI B J, TAN H Y. An overview on theory and algorithm of support vector machines. Journal of University of Electronic Science and Technology of China, 2011,40(1):2-10. (in Chinese) | |
| [45] | 刘勇洪, 牛铮, 王长耀. 基于MODIS数据的决策树分类方法研究与应用. 遥感学报, 2005(4):405-412. |
| LIU Y H, NIU Z, WANG C Y. Research and application of the decision tree classification using MODIS data. Journal of Remote Sensing, 2005(4):405-412. (in Chinese) | |
| [46] | 李勇, 刘战东, 张海军. 不平衡数据的集成分类算法综述. 计算机应用研究, 2014,31(5):1287-1291. |
| LI Y, LIU Z D, ZHANG H J. Review on ensemble algorithms for imbalanced data classification. Application Research of Computers, 2014,31(5):1287-1291. (in Chinese) | |
| [47] | 孙志军, 薛磊, 许阳明, 王正. 深度学习研究综述. 计算机应用研究, 2012,29(8):2806-2810. |
| SUN Z J, XUE L, XU Y M, WANG Z. Overview of deep learning. Application Research of Computers, 2012, 29(8):2806-2810. (in Chinese) | |
| [48] | XU J F, ZHANG Y J, MIAO D Q. Three-way confusion matrix for classification: A measure driven view. Information Sciences, 2020,507:772-794. |
| [49] | 赵小敏, 杨梅花. 江西省红壤地区主要土壤类型的高光谱特性研究. 土壤学报, 2018,55(1):31-42. |
| ZHAO X M, YANG M H. Hyper-spectral characteristics of major types of soils in red soil region of Jiangxi Province, China. Acta Pedologica Sinica, 2018,55(1):31-42. (in Chinese) | |
| [50] | 国佳欣, 赵小敏, 郭熙, 徐喆, 朱青, 江叶枫. 基于PLSR-BP复合模型的红壤有机质含量反演研究. 土壤学报, 2020,57(3):636-645. |
| GUO J X, ZHAO X M, GUO X, XU Z, ZHU Q, JIANG Y F. Inversion of organic matter content in red soil based on PLSR-BP composite model. Acta Pedologica Sinica, 2020,57(3):636-645. (in Chinese) | |
| [51] | 方匡南, 吴见彬, 朱建平, 谢邦昌. 随机森林方法研究综述. 统计与信息论坛, 2011,26(3):32-38. |
| FANG K N, WU J B, ZHU J P, XIE B C. A review of technologies on random forests. Statistics & Information Forum, 2011,26(3):32-38. (in Chinese) | |
| [52] | 叶志飞, 文益民, 吕宝粮. 不平衡分类问题研究综述. 智能系统学报, 2009,4(2):148-156. |
| YE Z F, WEN Y M, LÜ B L. A survey of imbalanced pattern classification problems. CAAI Transactions on Intelligent Systems, 2009, 4(2):148-156. (in Chinese) | |
| [53] | CHAWLA N V, JAPKOWICZ N, KOTCZ A. Editorial: Special issue on learning from imbalanced data sets. Acm Sigkdd Explorations Newsletter, 2004,6(1):1-6. |
| [1] | 杨改青, 王林枫, 李文清, 朱河水, 付彤, 廉红霞, 张立阳, 滕战伟, 张黎杰, 任宏, 徐新颖, 刘新鹤, 魏钰轩, 高腾云. 基于昼夜节律的牛奶品质研究[J]. 中国农业科学, 2023, 56(2): 379-390. |
| [2] | 黄翀,侯相君. 基于Bi-LSTM模型的时间序列遥感作物分类研究[J]. 中国农业科学, 2022, 55(21): 4144-4157. |
| [3] | 郭灿,岳晓凤,白艺珍,张良晓,张奇,李培武. 花生黄曲霉毒素平衡取样-随机森林风险预警模型的应用研究[J]. 中国农业科学, 2022, 55(17): 3426-3436. |
| [4] | 申哲,张认连,龙怀玉,徐爱国. 基于机器学习方法的宁夏南部土壤质地空间分布研究[J]. 中国农业科学, 2022, 55(15): 2961-2972. |
| [5] | 黄雨晴,孙艳艳,罗荣峥,阿旺措姆,卢素文,樊秀彩,王晨,刘崇怀,房经贵. 葡萄种质资源花穗形状分类标准的建立及其动态发育过程分析[J]. 中国农业科学, 2021, 54(11): 2389-2405. |
| [6] | 赵静,李志铭,鲁力群,贾鹏,杨焕波,兰玉彬. 基于无人机多光谱遥感图像的玉米田间杂草识别[J]. 中国农业科学, 2020, 53(8): 1545-1555. |
| [7] | 许世卫,邸佳颖,李干琼,庄家煜. 农产品监测预警模型集群构建理论方法与应用[J]. 中国农业科学, 2020, 53(14): 2859-2871. |
| [8] | 辛晓平,丁蕾,程伟,朱晓昱,陈宝瑞,刘钟龄,何广礼,青格勒,杨桂霞,唐华俊. 北方草地及农牧交错区草地植被碳储量及其影响因素[J]. 中国农业科学, 2020, 53(13): 2757-2768. |
| [9] | 姬旭升,李旭,万泽福,姚霞,朱艳,程涛. 基于高空间分辨率卫星影像的新疆阿拉尔市棉花与枣树分类[J]. 中国农业科学, 2019, 52(6): 997-1008. |
| [10] | 盛月凡,王海燕,乔鈜元,王玫,陈学森,沈向,尹承苗,毛志泉. 不同土壤质地对平邑甜茶幼苗连作障碍程度的影响[J]. 中国农业科学, 2019, 52(4): 715-724. |
| [11] | 王玉斌, 平俊爱, 牛皓, 楚建强, 杜志宏, 吕鑫, 李慧明, 张福耀. 粒用高粱种质中后期抗旱性鉴定筛选与分类指标评价[J]. 中国农业科学, 2019, 52(22): 4039-4049. |
| [12] | 邱鹏勋, 汪小钦, 茶明星, 李娅丽. 基于TWDTW的时间序列GF-1 WFV农作物分类[J]. 中国农业科学, 2019, 52(17): 2951-2961. |
| [13] | 杨珺雯,张锦水,潘耀忠,孙佩军,朱爽. 基于遥感识别误差校正面积的农作物种植面积抽样高效分层指标研究——以冬小麦为例[J]. 中国农业科学, 2018, 51(4): 675-687. |
| [14] | 刘庆飞,张宏立,王艳玲. 基于深度可分离卷积的实时农业图像逐像素分类研究[J]. 中国农业科学, 2018, 51(19): 3673-3682. |
| [15] | 何平,李林光,王海波,常源升,李慧峰. 遮光性套袋对桃果实转录组的影响[J]. 中国农业科学, 2017, 50(6): 1088-1097. |
|
||