






中国农业科学 ›› 2023, Vol. 56 ›› Issue (5): 951-963.doi: 10.3864/j.issn.0578-1752.2023.05.011
曹珂( ), 陈昌文, 杨选文, 别航灵, 王力荣()
), 陈昌文, 杨选文, 别航灵, 王力荣()
收稿日期:2022-04-28
接受日期:2022-09-09
出版日期:2023-03-01
发布日期:2023-03-13
通信作者:
王力荣,Tel:13700883956;E-mail:wanglirong@caas.cn
联系方式:
曹珂,Tel:13673618358;E-mail:wyandck@126.com。
基金资助:
CAO Ke(), CHEN ChangWen, YANG XuanWen, BIE HangLing, WANG LiRong()
Received:2022-04-28
Accepted:2022-09-09
Published:2023-03-01
Online:2023-03-13
摘要:
【背景】 桃单果重和可溶性固形物含量(SSC)是育种家关注的两个重要的数量性状,受到多个微效基因的控制,难以通过单个标记进行早期筛选。全基因组选择作为一种新颖的数量性状早期预测工具,在果树上已经有了初步应用,但其在桃上的应用效果以及影响预测准确性的因素仍需要深入探讨。【目的】 建立桃单果重和SSC的全基因组选择技术,为桃高效分子育种技术体系的建立奠定基础。【方法】 以520株训练自然群体为试材,通过重测序筛选出的48 398个SNP进行分型,在11个全基因组预测模型中分别筛选出两个数量性状适宜的模型,进而在56株自然群体和1 145株杂交群体上进行应用。【结果】 3类群体的平均测序数据量在1.95—3.52 Gb,测序深度为5.29—10.79×。训练自然群体经与参考基因组比对,共得到5 065 726个SNP,去除缺失率较高(>20%)、最小等位基因频率过低(<0.05)的位点后,随机挑选基因组上48 398个SNP用于训练群体的全基因组选择模型构建。单果重预测精度最高的模型是BayesA,SSC预测精度最高的模型为randomforest。分别利用两个数量性状最适的模型进行预测,发现在自然群体中,单果重的预测精度为0.4767—0.6141,高于SSC的0.3220—0.4329;而在杂交群体中,单果重的预测精度为0.2319—0.4870,同样高于SSC的0.0200—0.2793;该结果也表明利用训练自然群体构建的预测模型在预测自然群体上应用的精度高于杂交群体。进而以单果重为例,发现当育种目标是大果时,全基因组选择仅需保留17.78%的单株,效率明显高于单标记和双标记筛选。同时探讨了群体离散程度、遗传力和群体结构等对预测精度的影响,发现预测精度可能受到上述因子的综合影响。【结论】 本研究筛选出桃果实单果重和SSC适宜全基因组选择模型,表明该方法的选择效率明显高于单标记筛选,研究结果为两个数量性状的高效分子辅助育种奠定了理论和技术支撑。
曹珂, 陈昌文, 杨选文, 别航灵, 王力荣. 桃果实单果重及可溶性固形物含量的全基因组选择分析[J]. 中国农业科学, 2023, 56(5): 951-963.
CAO Ke, CHEN ChangWen, YANG XuanWen, BIE HangLing, WANG LiRong. Genomic Selection for Fruit Weight and Soluble Solid Contents in Peach[J]. Scientia Agricultura Sinica, 2023, 56(5): 951-963.
表1
本研究中所用材料的重测序结果"
| 群体类型 Population | 群体大小 Population size | 平均测序reads数 Average clean reads | 平均测序数据量 Average clean bases (Gb) | 平均测序深度 Mean depth (×) | 平均覆盖度 Coverage rate (%) |
|---|---|---|---|---|---|
| 训练自然群体 Training population | 520 | 21267611 | 2.96 | 7.76 | 79.57 |
| 预测自然群体 Predicted nature population | 56 | 14603168 | 1.95 | 5.29 | 78.22 |
| 预测杂交群体 Predicted cross population | 1145 | 23493089 | 3.52 | 10.79 | 89.58 |
表2
用于全基因组选择分析的SNP在染色体上的分布"
| Chr.1 | Chr.2 | Chr.3 | Chr.4 | Chr.5 | Chr.6 | Chr.7 | Chr.8 | |
|---|---|---|---|---|---|---|---|---|
| 染色体长度 Chromosome size (Mb) | 47.85 | 30.40 | 27.37 | 25.84 | 18.50 | 30.77 | 22.39 | 22.57 |
| SNP数目(个) SNP number | 8610 | 7133 | 5979 | 7095 | 3239 | 6294 | 5006 | 5042 |
| SNP密度(个/MB) SNP density (per Mb) | 179.93 | 234.59 | 218.47 | 274.54 | 175.11 | 204.57 | 223.60 | 223.35 |
图1
筛选后的SNPs在桃基因组上的分布"
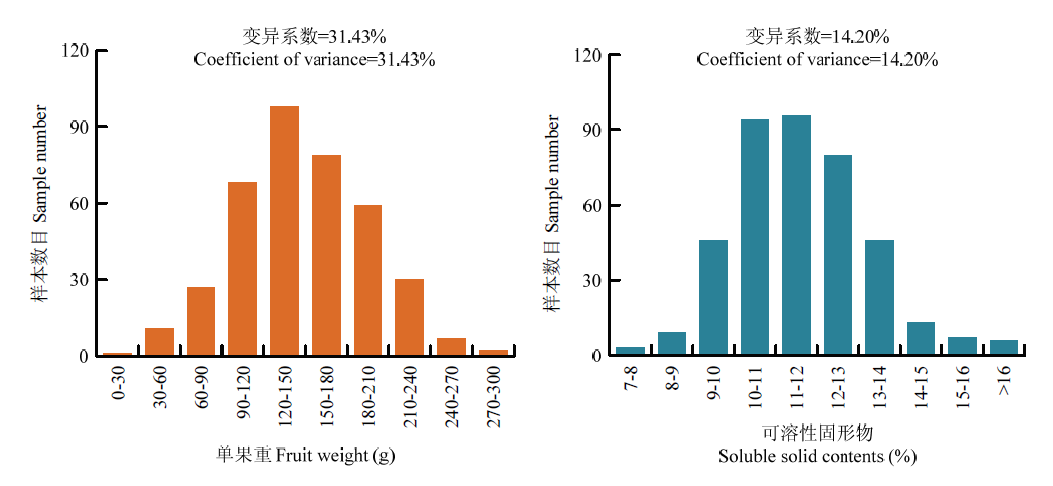
图2
训练群体两个数量性状的表型分布"
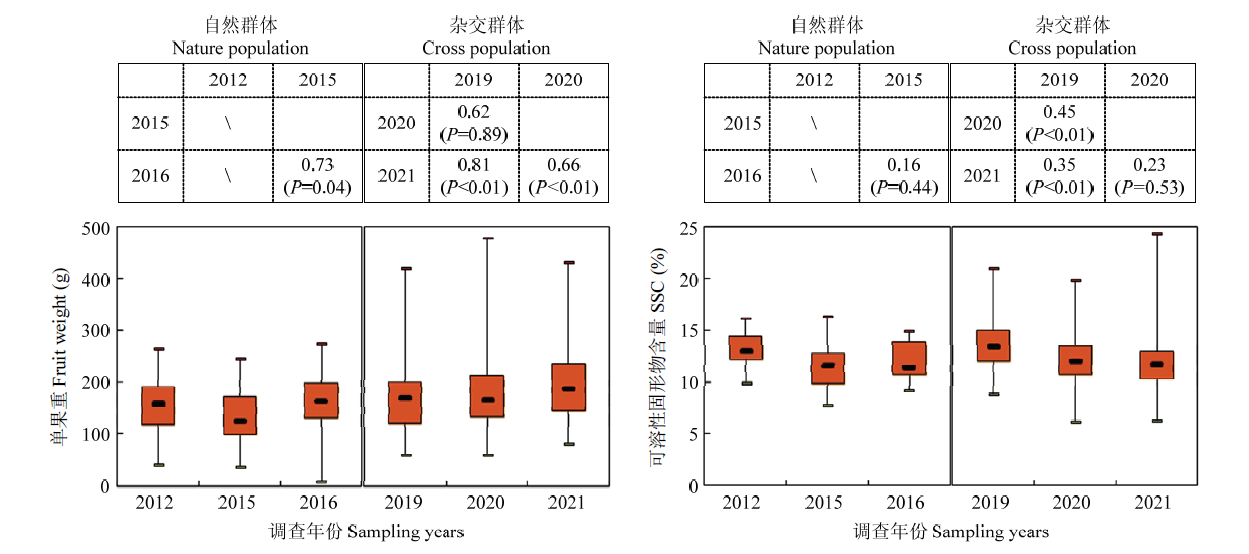
图3
两类预测群体的两个数量性状的表型分布 表格中显示为3年性状的相关性"
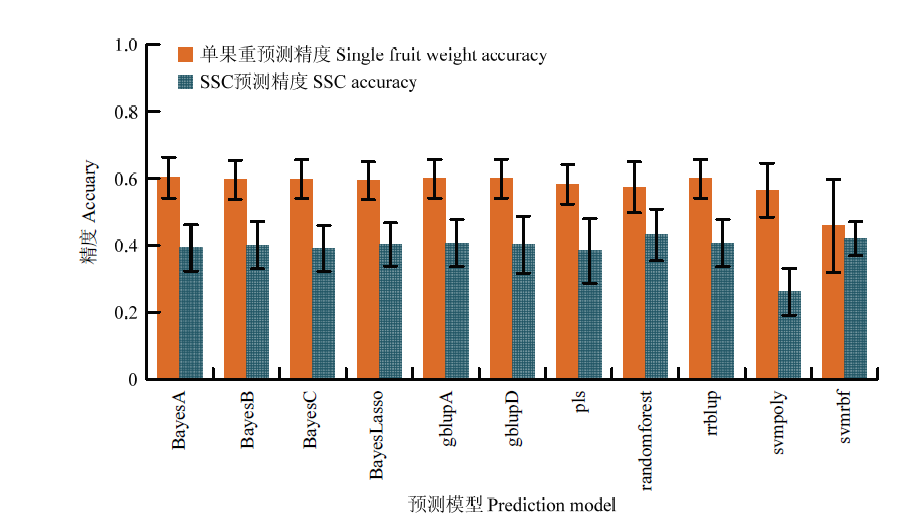
图4
两个数量性状采用不同预测模型的预测精度"
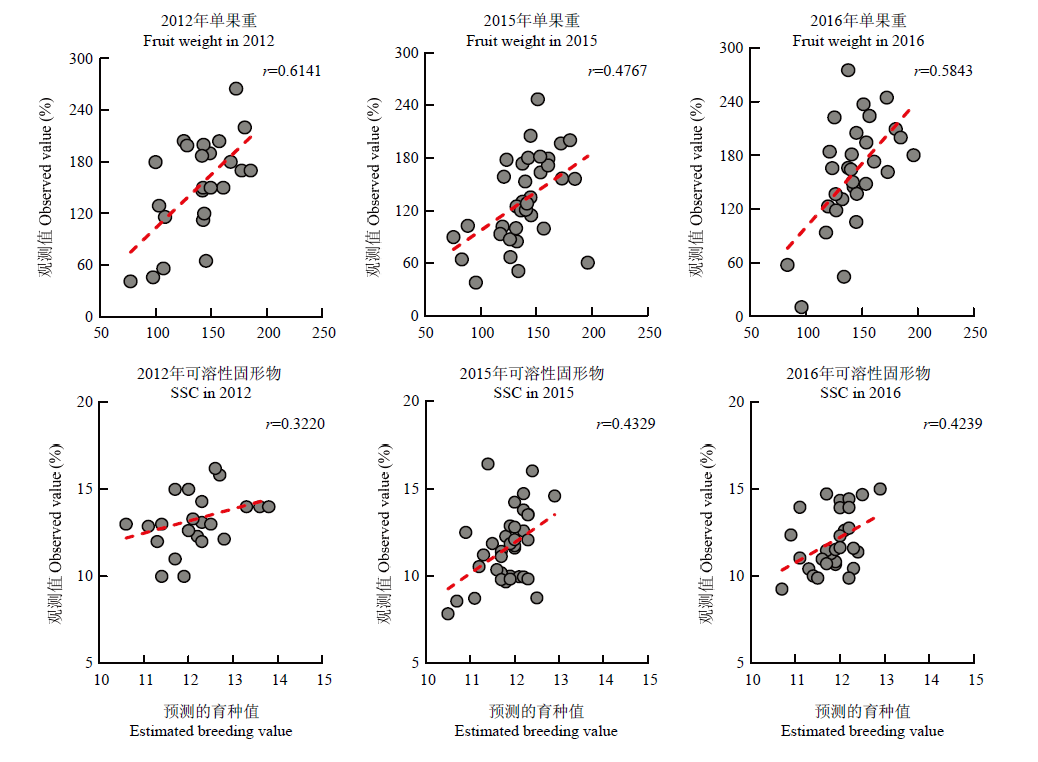
图5
预测自然群体两个数量性状的预测值与观测值的相关性分析"
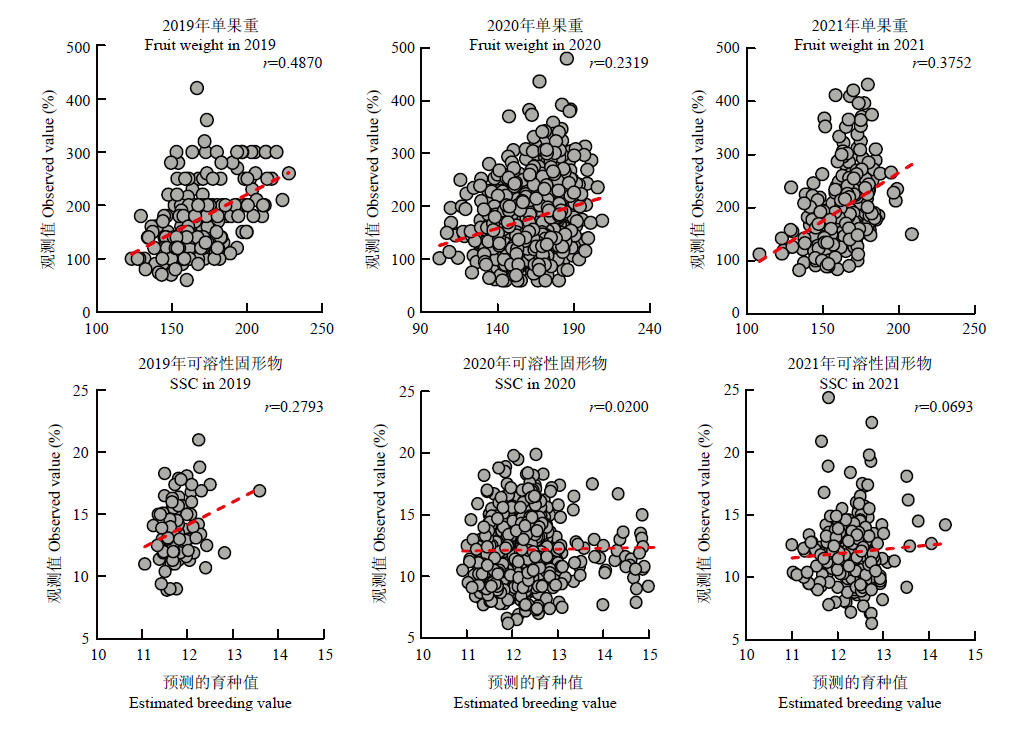
图6
预测杂交群体两个数量性状的预测值与观测值的相关性分析"
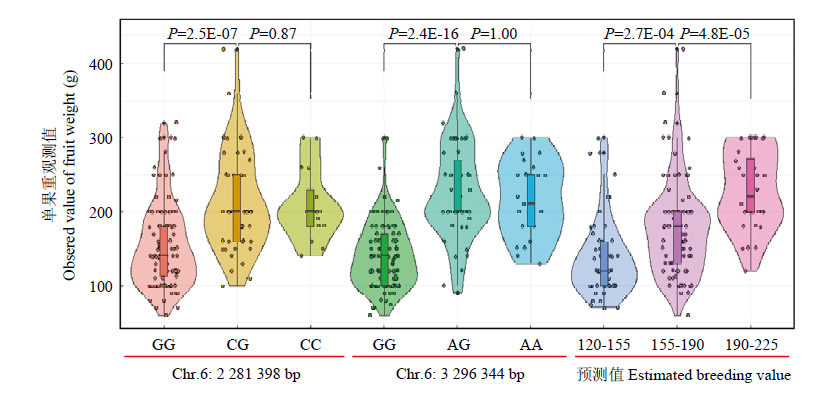
图7
单果重单标记筛选与全基因组选择的效率比较"
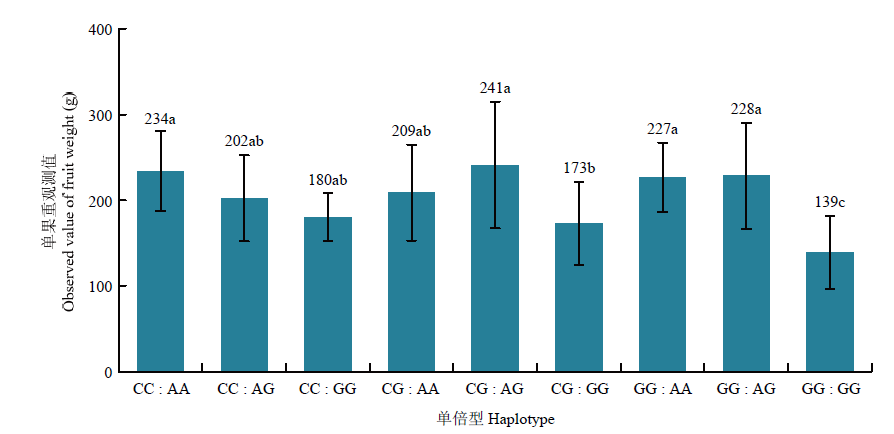
图8
两个已鉴定的单果重关联标记(Chr6: 2 281 398 bp和Chr6: 3 296 344 bp)组成的单倍型及其对应的表型 不同小写字母表示处理间差异显著(P<0.05)"
表3
不同杂交群体单果重的预测育种值与2020年观测值的相关性分析"
| 群体名称 Population name | 群体编号 Population number | 群体大小Population size | 相关性 Correlation index | 相关性阈值 Threshold of correlation index (P<0.05) |
|---|---|---|---|---|
| Honey Blaze×黄07-8东-9 Honey Blaze×Huang 07-8 Dong-9 | 1 | 30 | 0.14 | 0.355 |
| NJC83×C18 | 2 | 30 | 0.03 | 0.355 |
| Spring Prince×五月金 Spring Prince×Wu Yue Jin | 3 | 30 | 0.20 | 0.355 |
| 春雪×黄07-8东-9 Spring Snow×Huang 07-8 Dong-9 | 4 | 27 | -0.03 | 0.374 |
| 红不软×如皋油桃 Hong Bu Ruan×Rugao Zi You Tao | 5 | 30 | -0.15 | 0.355 |
| 华玉×中油桃16号 Hua Yu×Zhong You Tao 16# | 6 | 30 | 0.03 | 0.355 |
| 锦花×黄07-10西-48 Jin Hua×Huang 07-10 Xi-48 | 7 | 30 | -0.14 | 0.355 |
| 南二区西26-10×中油桃16号 Nan Er Qu Xi 26-10×Zhong You Tao 16# | 8 | 30 | 0.26 | 0.355 |
| 晴朗×中油蟠7号 Fairlane×Zhong You Pan 7 # | 9 | 29 | 0.22 | 0.361 |
| 晴朗×07-8东-9 Fairlane×07-8 Dong-9 | 10 | 99 | 0.20 | 0.197 |
| 瑞光39号×08-9-106 Rui Guang 39#×08-9-106 | 11 | 97 | -0.04 | 0.199 |
| 晚黄金×黄07-1-36 Wan Huang Jin×Huang 07-1-36 | 12 | 30 | 0.22 | 0.355 |
| 万州酸桃×石育白桃 Wanzhou Suan Tao×Shi Yu Bai Tao | 13 | 30 | -0.04 | 0.355 |
| 温07-2-30×中油墨玉 Wen07-2-30×Zhong You Mo Yu | 14 | 80 | -0.12 | 0.220 |
| 温08-7-58×01-9-11 Wen08-7-58×01-9-11 | 15 | 30 | -0.11 | 0.355 |
| 霞脆×中桃红玉 Xia Cui×Zhong Tao Hong Yu | 16 | 28 | 0.15 | 0.367 |
| 橡皮桃×Sweet Dream Xiang Pi Tao×Sweet Dream | 17 | 30 | 0.25 | 0.355 |
| 有明白桃×中油桃16号 Yumyeong×Zhong You Tao 16# | 18 | 30 | 0.18 | 0.355 |
| 郑油紫红桃×07区-7-6 Zheng You Zi Hong Tao×07 Qu-7-6 | 19 | 30 | -0.10 | 0.355 |
| 中桃红玉×黄07-8东-9 Zhong Tao Hong Yu×Huang 07-8 Dong-9 | 20 | 90 | 0.12 | 0.207 |
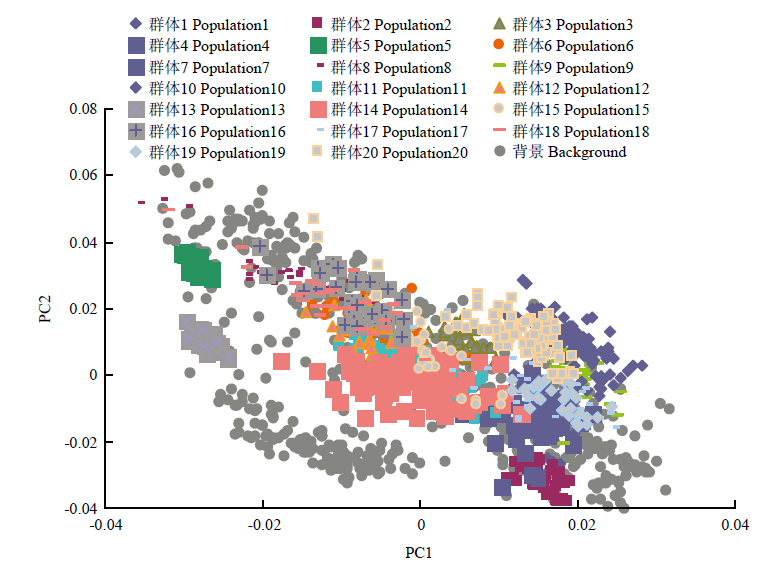
图9
共20个杂交群体的PCA分析"
| [1] |
苑兆和, 陈立德, 张心慧, 赵玉洁. 果树分子育种研究进展. 南京林业大学学报(自然科学版), 2021, 45(4): 1-12.
|
|
|
|
| [2] |
doi: 10.1371/journal.pone.0090574 |
| [3] |
doi: 10.1093/jxb/erw021 pmid: 26850878 |
| [4] |
doi: 10.1186/s13059-020-02169-y pmid: 33023652 |
| [5] |
doi: 10.1007/s001220050969 |
| [6] |
doi: 10.1007/s00122-004-1703-z |
| [7] |
doi: 10.1007/s11295-010-0334-6 |
| [8] |
doi: 10.1007/s11032-015-0271-z |
| [9] |
|
| [10] |
倪海枝, 王引, 颜帮国, 陈方永. 果树基因组辅助育种技术研究现状与展望. 分子植物育种, 2021, https://kns.cnki.net/kcms/detail/46.1068.S.20210416.1640.009.html.
|
|
|
|
| [11] |
张顺进, 寇浩玮, 丁晓婷, 刘贤, 蔡雯雯, 张子敬, 施巧婷, 茹宝瑞, 雷初朝, 黄永震. 全基因组选择技术在反刍动物遗传育种中的研究进展及其应用. 农业生物技术学报, 2021, 29(3): 571-578.
|
|
|
|
| [12] |
刘海岚, 夏超, 兰海. 全基因组选择技术在作物育种中的研究进展. 华北农学报, 2022, 37(增刊): 51-58.
|
|
|
|
| [13] |
张苗苗, 王军辉, 卢楠, 麻文俊, 王楠, 吴夏明. 林木全基因组选择研究现状和应用. 世界林业研究, 2021, 34(4): 26-32.
|
|
|
|
| [14] |
doi: 10.1371/journal.pone.0036674 |
| [15] |
doi: 10.1038/hortres.2015.60 pmid: 26744627 |
| [16] |
doi: 10.1186/s12864-017-3781-8 pmid: 28583089 |
| [17] |
doi: 10.1038/s41598-018-30154-w |
| [18] |
|
| [19] |
王力荣, 朱更瑞. 桃种质资源描述规范和数据标准. 北京: 中国农业出版社, 2005: 54-76.
|
|
|
|
| [20] |
doi: 10.1093/nar/8.19.4321 pmid: 7433111 |
| [21] |
doi: 10.1093/bioinformatics/bty560 |
| [22] |
|
| [23] |
doi: 10.1101/gr.107524.110 pmid: 20644199 |
| [24] |
doi: 10.1016/j.ajhg.2010.11.011 pmid: 21167468 |
| [25] |
doi: 10.1038/ng.2586 pmid: 23525075 |
| [26] |
doi: 10.1111/pbi.13112 pmid: 30950186 |
| [27] |
|
| [28] |
doi: 10.3389/fpls.2020.570871 |
| [29] |
doi: 10.3389/fpls.2018.00190 pmid: 29515606 |
| [30] |
doi: 10.1534/genetics.113.150078 pmid: 23934883 |
| [31] |
doi: 10.1186/1297-9686-43-26 |
| [32] |
doi: 10.2135/cropsci2011.05.0253 |
| [33] |
doi: 10.3835/plantgenome.2010.12.0029 |
| [34] |
doi: 10.1038/ncomms13246 pmid: 27824331 |
| [1] | 孙萍, 朱文灿, 林贤锐, 吴嘉颀, 曹译文, 陈辰斐, 王轶, 朱建锡, 贾惠娟, 钱敏杰, 沈建生. 基于代谢组和转录组解析多雨寡照对桃果皮着色和类黄酮积累的影响[J]. 中国农业科学, 2025, 58(6): 1173-1194. |
| [2] | 郭天发, 吴金龙, 仇倩倩, 马新超, 王力荣, 吴翠云. 新疆土桃果皮纯色形成与PpMYB10.1启动子变异的关系[J]. 中国农业科学, 2025, 58(2): 326-338. |
| [3] | 邹霈怡, 刘美艳, 王颖, 李然红. 狗枣猕猴桃AkNAC2的克隆及功能研究[J]. 中国农业科学, 2025, 58(19): 3985-3999. |
| [4] | 庄润杰, 刘慧铭, 王诗雨, 吕婉萍, 温永仙. 基于G2PSE堆叠集成的全基因组选择方法[J]. 中国农业科学, 2025, 58(15): 2960-2979. |
| [5] | 郭磊, 张斌斌, 沈志军, 严娟, 许建兰, 蔡志翔, 俞明亮, 王发林, 宋宏峰. 桃园绿肥连续还田后中微量元素释放特征及对土壤有效养分的影响[J]. 中国农业科学, 2025, 58(12): 2411-2426. |
| [6] | 廖锴, 李欣, 石延霞, 谢学文, 李磊, 范腾飞, 王绍辉, 李宝聚, 柴阿丽. 塑料拱棚不同通风方式对黄瓜细菌性角斑病传播的影响[J]. 中国农业科学, 2025, 58(10): 1934-1946. |
| [7] | 郭磊, 黄晨艳, 宋宏峰, 沈志军, 张斌斌, 马瑞娟, 孙朦, 何鑫, 俞明亮. 桃苗圃适用除草剂的筛选、混配与安全性评价[J]. 中国农业科学, 2024, 57(9): 1734-1747. |
| [8] | 肖刘华, 康乃慧, 李树成, 郑致远, 罗绕绕, 陈金印, 陈明, 向妙莲. 茉莉酸甲酯对猕猴桃果实抗葡萄座腔菌过程中能量代谢和膜脂代谢的影响[J]. 中国农业科学, 2024, 57(7): 1377-1393. |
| [9] | 安秀红, 孙妍, 王芳, 冯启科, 王宁, 李津津, 张俊佩, 王红霞. 河北省太行山区‘辽宁1号’核桃叶片营养诊断技术研究[J]. 中国农业科学, 2024, 57(6): 1153-1166. |
| [10] | 彭佳伟, 张叶, 寇单单, 杨丽, 刘晓飞, 张学英, 陈海江, 田义. ‘仓方早生’桃及其早熟芽变不同发育时期果实的转录组分析[J]. 中国农业科学, 2023, 56(5): 964-980. |
| [11] | 杨丽, 曹洪波, 张学英, 翟含含, 李辛淼, 彭佳伟, 田义, 陈海江. 桃生长势相关基因PpSAUR73功能鉴定[J]. 中国农业科学, 2023, 56(20): 4072-4086. |
| [12] | 刘针杉, 涂红霞, 周荆婷, 马艳, 柴久凤, 王旨意, 杨鹏飞, 杨小芹, Kumail Abbas, 王浩, 王燕, 王小蓉. 中国樱桃正反交F1代果实主要性状的遗传分析[J]. 中国农业科学, 2023, 56(2): 345-356. |
| [13] | 李仁静, 申晚霞, 赵婉彤, 程莉, 李沛, 江东. 利用SLAF-seq简化基因组数据挖掘甜橙果实品质性状基因[J]. 中国农业科学, 2023, 56(16): 3168-3182. |
| [14] | 刘苏宁, 别航灵, 王君秀, 陈雪嘉, 王新卫, 王力荣, 曹珂. 山桃杂交群体抗蚜优系的背景选择与标记优劣比较[J]. 中国农业科学, 2023, 56(15): 2995-3005. |
| [15] | 王朝晖, 李勇, 曹珂, 朱更瑞, 方伟超, 陈昌文, 王新卫, 吴金龙, 王力荣. 189份桃种质肉质性状形成相关位点基因型鉴定及组合分析[J]. 中国农业科学, 2023, 56(12): 2367-2379. |
|
||