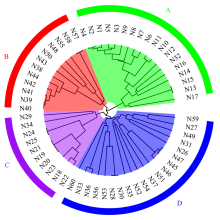
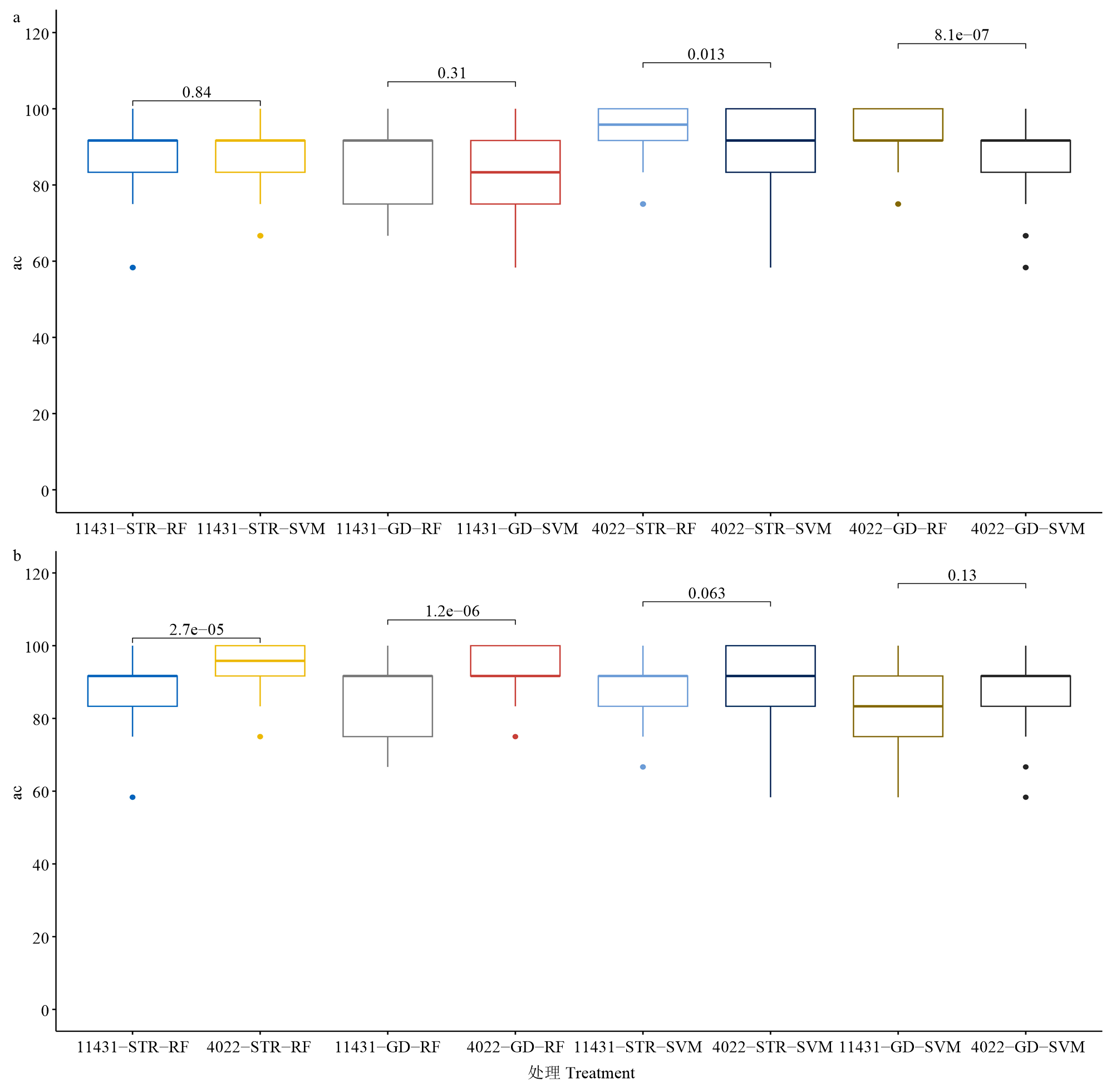
| [1] |
MELCHINGER A E, LEE M, LAMKEY K R, HALLAUER A R, WOODMAN W L. Genetic diversity for restriction fragment length polymorphisms and heterosis for two diallel sets of maize inbreds. Theoretical and Applied Genetics, 1990, 80(4): 488-496.
doi: 10.1007/BF00226750
pmid: 24221007
|
| [2] |
刘志斋, 吴迅, 刘海利, 李永祥, 李清超, 王凤格, 石云素, 宋燕春, 宋伟彬, 赵久然, 赖锦盛, 黎裕, 王天宇. 基于40个核心SSR标记揭示的820份中国玉米重要自交系的遗传多样性与群体结构. 中国农业科学, 2012, 45(11): 2107-2138. doi: 10.3864/j.issn.0578-1752.2012.11.001. |
|
LIU Z Z, WU X, LIU H L, LI Y X, LI Q C, WANG F G, SHI Y S, SONG Y C, SONG W B, ZHAO J R, LAI J S, LI Y, WANG T Y. Genetic diversity and population structure of important Chinese maize inbred lines revealed by 40 core simple sequence repeats (SSRs). Scientia Agricultura Sinica, 2012, 45(11): 2107-2138. doi: 10.3864/j.issn.0578-1752.2012.11.001. (in Chinese) |
| [3] |
赵久然, 李春辉, 宋伟, 王元东, 张如养, 王继东, 王凤格, 田红丽, 王蕊. 基于SNP芯片揭示中国玉米育种种质的遗传多样性与群体遗传结构. 中国农业科学, 2018, 51(4): 626-644. doi: 10.3864/j.issn.0578-1752.2018.04.003. |
|
ZHAO J R, LI C H, SONG W, WANG Y D, ZHANG R Y, WANG J D, WANG F G, TIAN H L, WANG R. Genetic diversity and population structure of important Chinese maize breeding germplasm revealed by SNP-chips. Scientia Agricultura Sinica, 2018, 51(4): 626-644. doi: 10.3864/j.issn.0578-1752.2018.04.003. (in Chinese)
|
| [4] |
杨亚桐, 董安忆, 刘松涛, Zenda Tinashe, 段会军. 基于SSR分子标记的糯玉米遗传多样性研究. 江苏农业科学, 2020, 48(2): 83-86.
|
|
YANG Y T, DONG A Y, LIU S T, TINASHE Z, DUAN H J. Study on genetic diversity of waxy corn based on simple sequence repeats (SSR) molecular markers. Jiangsu Agricultural Sciences, 2020, 48(2): 83-86. (in Chinese)
|
| [5] |
卢柏山, 史亚兴, 宋伟, 徐丽, 赵久然. 利用SNP标记划分甜玉米自交系的杂种优势类群. 玉米科学, 2015, 23(1):58-62, 68.
|
|
LU B S, SHI Y X, SONG W, XU L, ZHAO J R. Heterotic grouping of sweet corn inbred lines by SNP markers. Journal of Maize Sciences, 2015, 23(1): 58-62, 68. (in Chinese)
|
| [6] |
徐磊, 徐志军, 安东升, 胡小文, 高玉尧, 刘洋. 基于SNP标记的糯玉米指纹图谱构建和遗传多样性分析. 分子植物育种, 2022, 20(19):6405-6414.
|
|
XU L, XU Z J, AN D S, HU X W, GAO Y Y, LIU Y. Fingerprints construction and genetic diversity analysis of waxy corns based on SNP markers. Molecular Plant Breeding, 2022, 20(19): 6405-6414. (in Chinese)
|
| [7] |
卢媛, 艾为大, 韩晴, 王义发, 李宏杨, 瞿玉玑, 施标, 沈雪芳. 糯玉米自交系SSR标记遗传多样性及群体遗传结构分析. 作物学报, 2019, 45(2):214-224.
doi: 10.3724/SP.J.1006.2019.83008
|
|
LU Y, AI W D, HAN Q, WANG Y F, LI H Y, QU Y J, SHI B, SHEN X F. Genetic diversity and population structure analysis by SSR markers in waxy maize. Acta Agronomica Sinica, 2019, 45(2): 214-224. (in Chinese)
|
| [8] |
李扬. 机器学习在农业领域应用现状与前景. 安徽农学通报, 2021, 27(1):164-165, 174.
|
|
LI Y. Application status and prospect of machine learning in agriculture. Anhui Agricultural Science Bulletin, 2021, 27(1): 164-165, 174. (in Chinese)
|
| [9] |
薛菁菁, 陈慧敏, 孔令怡, 樊欣怡, 聂飞平. 机器学习的基石: 聚类任务的现状与挑战. 科学观察, 2024, 19(1):4-17.
doi: 10.15978/j.cnki.1673-5668.202401002
|
|
XUE J J, CHEN H M, KONG L Y, FAN X Y, NIE F P. The foundation of machine learning: current status and challenges in clustering tasks. Science Focus, 2024, 19(1): 4-17. (in Chinese)
|
| [10] |
BRADBURY P J, ZHANG Z W, KROON D E, CASSTEVENS T M, RAMDOSS Y, BUCKLER E S. TASSEL: Software for association mapping of complex traits in diverse samples. Bioinformatics, 2007, 23(19): 2633-2635.
doi: 10.1093/bioinformatics/btm308
pmid: 17586829
|
| [11] |
ALEXANDER D H, NOVEMBRE J, LANGE K. Fast model-based estimation of ancestry in unrelated individuals. Genome Research, 2009, 19(9): 1655-1664.
doi: 10.1101/gr.094052.109
pmid: 19648217
|
| [12] |
JOMBART T. Adegenet: A R package for the multivariate analysis of genetic markers. Bioinformatics, 2008, 24(11): 1403-1405.
doi: 10.1093/bioinformatics/btn129
pmid: 18397895
|
| [13] |
TEAM R. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing, 2014.
|
| [14] |
YU G C, SMITH D K, ZHU H C, GUAN Y, LAM T T Y. Ggtree: an r package for visualization and annotation of phylogenetic trees with their covariates and other associated data. Methods in Ecology and Evolution, 2017, 8(1): 28-36.
|
| [15] |
LIAW A, WIENER M. Classification and regression by randomForest. R News, 2002, 2: 18-22.
|
| [16] |
KUHN M. Building predictive models in r using the caret package. Journal of Statistical Software, 2008, 28(5): 1-26.
|
| [17] |
李念念, 王义波, 徐国平, 易黎, 王爱方, 李婷, 曹刚强. 基于SNP标记的玉米自交系类群划分方法和分群功效评估指标的比较. 植物遗传资源学报, 2020, 21(3):605-618.
doi: 10.13430/j.cnki.jpgr.20190618003
|
|
LI N N, WANG Y B, XU G P, YI L, WANG A F, LI T, CAO G Q. Comparison of different grouping procedures and evaluation criteria for grouping maize inbreds using SNP data. Journal of Plant Genetic Resources, 2020, 21(3): 605-618. (in Chinese)
|
| [18] |
钟昌松, 徐利远, 余桂蓉, 杜文平, 蒲志刚, 李琳. 20份特用玉米自交系亲缘关系的SSR标记研究. 玉米科学, 2006, 14(4):43-46.
|
|
ZHONG C S, XU L Y, YU G R, DU W P, PU Z G, LI L. Genetic relationship among 20 special maize inbreds studied by SSR markers. Journal of Maize Sciences, 2006, 14(4): 43-46. (in Chinese)
|
| [19] |
赵文明, 王森, 陈艳萍, 张美景, 袁建华. 基于60个核心SSR标记的糯玉米自交系遗传多样性分析. 江西农业学报, 2018, 30(12):1-8.
|
|
ZHAO W M, WANG S, CHEN Y P, ZHANG M J, YUAN J H. Genetic diversity analysis of waxy corn inbred lines based on 60 core SSR markers. Acta Agriculturae Jiangxi, 2018, 30(12): 1-8. (in Chinese)
|
| [20] |
史亚兴, 卢柏山, 宋伟, 徐丽, 赵久然. 基于SNP标记技术的糯玉米种质遗传多样性分析. 华北农学报, 2015, 30(3): 77-82.
doi: 10.7668/hbnxb.2015.03.015
|
|
SHI Y X, LU B S, SONG W, XU L, ZHAO J R. Acta Agriculturae Boreali-Sinica, 2015, 30(3): 77-82. (in Chinese)
|
| [21] |
孙佩, 张培风, 张玉红, 周联东, 王蕊, 王文洁, 张瑞平, 李祥, 马朝阳, 李合顺, 王学军. 基于SNP标记的玉米自交系S155、PHA458和A01的遗传多样性分析. 陕西农业科学, 2023, 69(9):1-7.
|
|
SUN P, ZHANG P F, ZHANG Y H, ZHOU L D, WANG R, WANG W J, ZHANG R P, LI X, MA C Y, LI H S, WANG X J. Genetic diversity analysis of maize inbred lines S155, PHA458 and A01 based on SNP markers. Shaanxi Journal of Agricultural Sciences, 2023, 69(9): 1-7. (in Chinese)
|
| [22] |
肖颖妮, 于永涛, 谢利华, 祁喜涛, 李春艳, 文天祥, 李高科, 胡建广. 基于SNP标记揭示中国鲜食玉米品种的遗传多样性. 作物学报, 2022, 48(6):1301-1311.
doi: 10.3724/SP.J.1006.2022.13031
|
|
XIAO Y N, YU Y T, XIE L H, QI X T, LI C Y, WEN T X, LI G K, HU J G. Genetic diversity analysis of Chinese fresh corn hybrids using SNP Chips. Acta Agronomica Sinica, 2022, 48(6): 1301-1311. (in Chinese)
|
| [23] |
李余良, 索海翠, 韩福光, 刘建华, 胡建广, 高磊, 李武. 基于SLAF-seq技术分析甜、糯玉米种质遗传多样性. 玉米科学, 2019, 27(4):71-78.
|
|
LI Y L, SUO H C, HAN F G, LIU J H, HU J G, GAO L, LI W. Analysis of genetic diversity of sweet and wax corn germplasms using SLAF-seq technology. Journal of Maize Sciences, 2019, 27(4): 71-78. (in Chinese)
|
| [24] |
王欣, 徐一亿, 徐扬, 徐辰武. 作物全基因组选择育种技术研究进展. 生物技术通报, 2024, 40(3):1-13.
doi: 10.13560/j.cnki.biotech.bull.1985.2023-1079
|
|
WANG X, XU Y Y, XU Y, XU C W. Research progress in genomic selection breeding technology for crops. Biotechnology Bulletin, 2024, 40(3): 1-13. (in Chinese)
|
| [25] |
YIN L L, ZHANG H H, ZHOU X, YUAN X H, ZHAO S H, LI X Y, LIU X L. KAML: improving genomic prediction accuracy of complex traits using machine learning determined parameters. Genome Biology, 2020, 21(1): 146.
doi: 10.1186/s13059-020-02052-w
pmid: 32552725
|







 ), 张建国1, 于滔1, 杨耿斌1, 李文跃1, 马雪娜1, 孙艳杰4, 韩微波2, 唐贵3, 单大鹏4
), 张建国1, 于滔1, 杨耿斌1, 李文跃1, 马雪娜1, 孙艳杰4, 韩微波2, 唐贵3, 单大鹏4