






中国农业科学 ›› 2023, Vol. 56 ›› Issue (2): 217-235.doi: 10.3864/j.issn.0578-1752.2023.02.002
林萍( ),王开良,姚小华,任华东()
),王开良,姚小华,任华东()
收稿日期:2022-08-25
接受日期:2022-10-24
出版日期:2023-01-16
发布日期:2023-02-07
联系方式:
林萍,Tel:0571-63320229;E-mail:linping80@126.com。
基金资助:
LIN Ping(),WANG KaiLiang,YAO XiaoHua,REN HuaDong()
Received:2022-08-25
Accepted:2022-10-24
Published:2023-01-16
Online:2023-02-07
摘要:
【目的】近年来,油茶(Camellia oleifera)产业发展迅速,已成为中国四大油料之一。油茶良种不断涌现,但品质参差不齐,“同名异物、同物异名”等现象时有发生。建立油茶品种资源的单核苷酸多态性(single-nucleotide polymorphism,SNP)分子标记数据库,筛选重要SNP位点,开发油茶品种资源DNA指纹图谱,构建油茶品种资源的分子身份证,为品种鉴别、品种追溯等提供分子水平鉴别技术支撑。【方法】以221份普通油茶品种资源为材料,提取未成熟种子RNA,进行转录组测序。以二倍体南荣油茶基因组为参考,识别供试油茶品种资源的SNP位点并基因分型,利用SNP数据分析油茶群体及亚群的遗传多样性,分析SNP位点的观测杂合度、期望杂合度、多态信息含量(PIC)等信息,筛选核心SNP位点并采用Sanger测序验证,得到最优SNP位点组合后,结合品种资源基本信息构建油茶品种资源分子身份证。【结果】从油茶转录组中共检测到1 849 953个高质量SNP位点。群体遗传多样性分析发现,油茶群体观测杂合度为0.2966,期望杂合度为0.2462,固定指数为-0.2048,PIC为0.2073,最小等位基因频率为0.1648。参试群体的各亚群间遗传分化较小,存在较高的基因流,主要变异存在于亚群内。根据PIC、连锁不平衡衰退距离(LD)等参数从所有SNP位点中筛选出31个多态性高的核心位点,Sanger测序验证其中8个核心位点基因分型的准确率在91.36%以上。利用核心位点组成DNA指纹图谱,可区分出全部参试油茶品种资源。DNA指纹图谱结合油茶品种资源基本信息,构建成由66位数字组成的油茶品种资源分子身份证。【结论】依据SNP标记的PIC、LD等指标,筛选出31个核心SNP位点,精准区分全部供试油茶品种资源。将31个SNP位点所构建的油茶品种资源DNA指纹图谱与品种资源的起源、资源类型和亚群分布等基本属性信息相结合,构建了每份油茶品种资源唯一的分子身份证,并生成相应的条形码和二维码。
林萍, 王开良, 姚小华, 任华东. 基于转录组SNP构建油茶主要品种资源的分子身份证[J]. 中国农业科学, 2023, 56(2): 217-235.
LIN Ping, WANG KaiLiang, YAO XiaoHua, REN HuaDong. Development of DNA Molecular ID in Camellia oleifera Germplasm Based on Transcriptome-Wide SNPs[J]. Scientia Agricultura Sinica, 2023, 56(2): 217-235.
表1
油茶群体的遗传多样性参数"
| 群体 Pop | 样本数 Sample No. | Na | Ne | Ho | He | F-index | Nei | π | PIC | Shannon | MAF | SNP位点数 SNP No. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 亚群Ⅰ Subpop Ⅰ | 46 | 1.3064 | 1.3728 | 0.2958 | 0.2431 | -0.2169 | 0.2464 | 0.000158 | 0.2039 | 0.3922 | 0.1654 | 1849953 |
| 亚群Ⅱ Subpop Ⅱ | 31 | 1.3064 | 1.374 | 0.2973 | 0.2427 | -0.2250 | 0.2475 | 0.000158 | 0.2032 | 0.3903 | 0.1679 | 1849953 |
| 亚群Ⅲ Subpop Ⅲ | 38 | 1.3006 | 1.3662 | 0.2906 | 0.2383 | -0.2198 | 0.2422 | 0.000155 | 0.1998 | 0.3845 | 0.1638 | 1849953 |
| 亚群Ⅳ Subpop Ⅳ | 35 | 1.307 | 1.3717 | 0.2965 | 0.2417 | -0.2268 | 0.246 | 0.000157 | 0.2025 | 0.3893 | 0.1664 | 1849953 |
| 亚群Ⅴ Subpop Ⅴ | 42 | 1.3104 | 1.3772 | 0.3011 | 0.2449 | -0.2297 | 0.2484 | 0.000159 | 0.205 | 0.3939 | 0.1678 | 1849953 |
| 亚群Ⅵ Subpop Ⅵ | 15 | 1.3105 | 1.3751 | 0.3013 | 0.2396 | -0.2578 | 0.2497 | 0.000160 | 0.1992 | 0.3807 | 0.1817 | 1849925 |
| 亚群Ⅶ Subpop Ⅶ | 8 | 1.2989 | 1.3573 | 0.2893 | 0.2234 | -0.2950 | 0.2426 | 0.000155 | 0.1840 | 0.3484 | 0.2076 | 1843321 |
| 亚群Ⅷ Subpop Ⅷ | 5 | 1.3037 | 1.3504 | 0.2945 | 0.2102 | -0.4010 | 0.2397 | 0.000152 | 0.1700 | 0.3186 | 0.2526 | 1774982 |
| 全体 All | 220 | 1.3062 | 1.3739 | 0.2966 | 0.2462 | -0.2048 | 0.2468 | - | 0.2073 | 0.3991 | 0.1648 | 1849953 |

图1
油茶群体转录组内SNP的统计特征 A:SNP变异类型统计;B:SNP在基因组上的分布位置统计;C:位于基因编码区的SNP的功能统计"
表2
油茶亚群间遗传分化指数Fst(上三角)与基因流Nm(下三角)"
| 群体 Pop | 亚群Ⅰ Subpop Ⅰ | 亚群Ⅱ Subpop Ⅱ | 亚群Ⅲ Subpop Ⅲ | 亚群Ⅳ Subpop Ⅳ | 亚群Ⅴ Subpop Ⅴ | 亚群Ⅵ Subpop Ⅵ | 亚群Ⅶ Subpop Ⅶ | 亚群Ⅷ Subpop Ⅷ |
|---|---|---|---|---|---|---|---|---|
| 亚群Ⅰ SubpopⅠ | - | 0.0015 | 0.0040 | 0.0022 | 0.0047 | 0.0000 | 0.0000 | 0.0058 |
| 亚群Ⅱ Subpop Ⅱ | 161.8740 | - | 0.0035 | 0.0010 | 0.0028 | 0.0001 | 0.0000 | 0.0064 |
| 亚群Ⅲ Subpop Ⅲ | 62.6660 | 71.1826 | - | 0.0034 | 0.0046 | 0.0015 | 0.0000 | 0.0085 |
| 亚群Ⅳ Subpop Ⅳ | 115.9860 | 247.3711 | 73.8063 | - | 0.0033 | 0.0000 | 0.0000 | 0.0060 |
| 亚群Ⅴ Subpop Ⅴ | 52.9548 | 88.4173 | 53.6558 | 74.4734 | - | 0.0004 | 0.0000 | 0.0080 |
| 亚群Ⅵ Subpop Ⅵ | - | 4343.6263 | 168.3339 | - | 686.0412 | - | 0.0000 | 0.0045 |
| 亚群Ⅶ Subpop Ⅶ | - | - | - | - | - | - | - | 0.0012 |
| 亚群Ⅷ Subpop Ⅷ | 42.7958 | 38.8365 | 29.1307 | 41.2443 | 30.9227 | 55.1133 | 217.1238 | - |
表3
31个核心SNP位点及其详细信息"
| 序号 No. | 核心位点 Loci | PIC | 染色体 Chr. | 等位基因 Alleles | 位置 Location | 所在的基因 Gene | 基因注释 Gene annotation | 功能类型 Function_type | 功能 Function | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SNP-1-16341109 | 0.4701 | Chr.1 | A/G | 外显子 Exonic | Scaffold 1-snap-gene-163.21 | 异青霉素N合酶 Isopenicillin N synthase | 非同义突变 Nonsynonymous | 外显子1:c.A137G:p.N46S * Exon1: c.A137G:p.N46S | |||
| 2 | SNP-1-22551920 | 0.4890 | Chr.1 | C/T | 5′非编码区 5′UTR | Scaffold 1-snap-gene-225.31 | 丝状植物蛋白7亚型X2 Filament-like plant protein 7 isoform X2 | - | c.-1603G>A# | |||
| 3 | SNP-1-34038354 | 0.4867 | Chr.1 | T/A | 3′非编码区 3′UTR | Scaffold 1-snap-gene-340.25 | GATA转录组因子28 GATA transcription factor 28-like | - | c.1337T>A& | |||
| 4 | SNP-1-49052505 | 0.4941 | Chr.1 | A/G | 外显子 Exonic | Scaffold 1-snap-gene-490.28 | 磷酸核糖胺-甘氨酸连接酶 Phosphoribosylamine-glycine ligase | 同义突变 Synonymous | 外显子5:c.T1368C:p.H456H Exon5:c.T1368C:p.H456H | |||
| 5 | SNP-1-110833857 | 0.4679 | Chr.1 | G/C | 外显子 Exonic | Scaffold 1-snap-gene-1108.1 | 40S核糖体蛋白s24-1 40S ribosomal protein s24-1 | 同义突变 Synonymous | 外显子3:c.C117G:p.A39A Exon3:c.C117G:p.A39A | |||
| 6 | SNP-1-115890029 | 0.4882 | Chr.1 | A/G | 外显子 Exonic | Scaffold 1-processed-gene-1159.31 | - | 同义突变 Synonymous | 外显子1:c.T369C:p.G123G Exon1:c.T369C:p.G123G | |||
| 7 | SNP-1-188555309 | 0.4968 | Chr.1 | T/G | 3′非编码区 3′UTR | Scaffold 1-snap-gene-1885.48 | ATP依赖的DNA解旋酶2亚基KU80 ATP-dependent DNA helicase 2 subunit KU80 | - | c. 104A>C | |||
| 8 | SNP-2-4697104 | 0.4656 | Chr.2 | T/A | 5′非编码区 5′UTR | Scaffold 2-snap-gene-47.0 | 通用应激蛋白a相似蛋白 Universal stress protein a-like protein | - | c.-51T>A | |||
| 9 | SNP-2-102046792 | 0.4620 | Chr.2 | C/A | 3′非编码区 3′UTR | Scaffold 2-snap-gene-1020.8 | 胼胝质合成酶12 Callose synthase 12 | - | c.121C>A | |||
| 10 | SNP-3-58564519 | 0.4883 | Chr.3 | C/T | 外显子 Exonic | Scaffold 3-processed-gene-585.38 | 未知蛋白LOC103487192 Uncharacterized protein LOC103487192 | 同义突变 Synonymous | 外显子3:c.G201A:p.V67V Exon3:c.G201A:p.V67V | |||
| 11 | SNP-4-5589980 | 0.4644 | Chr.4 | T/G | 外显子 Exonic | Scaffold 4-snap-gene-56.9 | 嘌呤通透酶4 Probable purine permease 4 | 同义突变 Synonymous | 外显子2:c.A1131C:p.G377G Exon2:c.A1131C:p.G377G | |||
| 12 | SNP-5-59238652 | 0.4836 | Chr.5 | G/C | 外显子 Exonic | Scaffold 5-snap-gene-592.4 | 40s核糖体蛋白s8 40s ribosomal protein s8 | 同义突变 Synonymous | 外显子3:c.C417G:p.V139V Exon3:c.C417G:p.V139V | |||
| 13 | SNP-5-135461353 | 0.4702 | Chr.5 | T/C | 外显子 Exonic | Scaffold 5-snap-gene-1354.5 | 驱动蛋白近似蛋白KIN-7N Kinesin-like protein KIN-7N | 同义突变 Synonymous | 外显子17:c.A1842G:p.S614S Exon17:c.A1842G:p.S614S | |||
| 14 | SNP-5-175443498 | 0.4721 | Chr.5 | T/G | 5′非编码区 5′UTR | Scaffold 5-processed-gene-1754.17 | 黄酮3-羟化酶 Flavanone 3-hydroxylase | - | c.-19T>G | |||
| 15 | SNP-6-123202382 | 0.4872 | Chr.6 | A/C | 外显子 Exonic | Scaffold 6-snap-gene-1232.1 | RNA聚合酶Ⅱ转录亚基1中间体 Mediator of RNA polymerase II transcription subunit 1 | 非同义突变 Nonsynonymous | 外显子8:c.A1694C:p.K565T Eon8:c.A1694C:p.K565T | |||
| 16 | SNP-6-125991240 | 0.4871 | Chr.6 | T/C | 外显子 Exonic | Scaffold 6-snap-gene-1260.11 | 寡肽转运体4 Oligopeptide transporter 4 | 非同义突变 Nonsynonymous | 外显子3:c.T821C:p.V274A Exon3:c.T821C:p.V274A | |||
| 17 | SNP-7-134929316 | 0.4606 | Chr.7 | T/C | 外显子 Exonic | Scaffold 7-snap-gene-1349.44 | 辅素样蛋白1亚型 Auxilin-like protein 1 isoform X1 | 同义突变 Synonymous | 外显子2:c.A2022G:p.Q674Q Exon2:c.A2022G:p.Q674Q | |||
| 序号 No. | 核心位点 Loci | PIC | 染色体 Chr. | 等位基因 Alleles | 位置 Location | 所在的基因 Gene | 基因注释 Gene annotation | 功能类型 Function_type | 功能 Function | |||
| 18 | SNP-8-37227126 | 0.4672 | Chr.8 | C/T | 外显子 Exonic | Scaffold 8-snap-gene-372.3 | 2-甲基丁醛肟单氧化酶 2-methylbutanal oxime monooxygenase | 非同义突变 Nonsynonymous | 外显子2:c.G949A:p.V317I Exon2:c.G949A:p.V317I | |||
| 19 | SNP-9-10583849 | 0.4926 | Chr.9 | A/T | 外显子 Exonic | Scaffold 9-snap-gene-105.30 | 磷脂转运ATP酶4 Probable phospholipid-transporting ATPase 4 | 同义突变 Synonymous | 外显子:7:c.T2460A:p.T820T Exon7:c.T2460A:p.T820T | |||
| 20 | SNP-9-23224047 | 0.4819 | Chr.9 | T/C | 外显子 Exonic | Scaffold 9-snap-gene-232.15 | 水解酶6结构域包含蛋白 Abhydrolase_6 domain-containing protein | 同义突变 Synonymous | 外显子3:c.T450C:p.L150L Exon3:c.T450C:p.L150L | |||
| 21 | SNP-9-89305797 | 0.4999 | Chr.9 | T/C | 外显子 Exonic | Scaffold 9-snap-gene-893.6 | 抗病性蛋白 Disease resistance protein | 非同义突变 Nonsynonymous | 外显子2:c.A496G:p.S166G Exon2:c.A496G:p.S166G | |||
| 22 | SNP-9-95564863 | 0.4817 | Chr.9 | G/T | 外显子 Exonic | Scaffold 9-snap-gene-955.13 | 复制蛋白A 70kDa DNA结合亚基B Replication protein A 70 kDa DNA-binding subunit B | 非同义突变 Nonsynonymous | 外显子13:c.C1768A:p.H590N Exon13:c.C1768A:p.H590N | |||
| 23 | SNP-10-146191194 | 0.4586 | Chr.10 | G/C | 外显子 Exonic | Scaffold 10-processed-gene-1462.14 | 未知蛋白LOC100853376 Uncharacterized protein LOC100853376 | 非同义突变 Nonsynonymous | 外显子1:c.G85C:p.D29H Exon1:c.G85C:p.D29H | |||
| 24 | SNP-11-126349400 | 0.4999 | Chr.11 | C/T | 外显子 Exonic | Scaffold 11-snap-gene-1263.11 | 未知蛋白LOC107417301亚型X1 Uncharacterized protein LOC107417301 isoform X1 | 同义突变 Synonymous | 外显子3:c.C1398T:p.F466F Exon3:c.C1398T:p.F466F | |||
| 25 | SNP-11-150316502 | 0.4675 | Chr.11 | G/A | 外显子 Exonic | Scaffold 11-snap-gene-1503.37 | 细胞色素P450 CYP72A219 Cytochrome P450 CYP72A219 | 同义突变 Synonymous | 外显子6:c.G465A:p.Q155Q Exon6:c.G465A:p.Q155Q | |||
| 26 | SNP-11-175529761 | 0.4925 | Chr.11 | G/C | 外显子 Exonic | Scaffold 11-snap-gene-1755.2 | mRNA去壳蛋白4增强子 Enhancer of mRNA-decapping protein 4-like | 非同义突变 Nonsynonymous | 外显子12:c.G4011C:p.K1337N Exon12:c.G4011C:p.K1337N | |||
| 27 | SNP-12-38432972 | 0.4699 | Chr.12 | C/G | 外显子 Exonic | Scaffold 12-snap-gene-384.1 | 多药物和有毒物质排出转运 Multidrug and toxic extrusion transporter | 同义突变 Synonymous | 外显子1:c.G132C:p.S44S Exon1:c.G132C:p.S44S | |||
| 28 | SNP-12-88588135 | 0.4907 | Chr.12 | G/A | 5′非编码区 5′UTR | Scaffold 12-snap-gene-885.8 | 网状内皮素相似蛋白B5 Reticulon-like protein B5 | - | c.-74C>T | |||
| 29 | SNP-13-180557942 | 0.4952 | Chr.13 | T/C | 外显子 Exonic | Scaffold 13-snap-gene-1805.53 | 富含半胱氨酸/组氨酸的C1结构域家族蛋白 Cysteine/Histidine-rich C1 domain family protein | 同义突变 Synonymous | 外显子3:c.T1047C:p.Y349Y Exon3:c.T1047C:p.Y349Y | |||
| 30 | SNP-14-86914708 | 0.4819 | Chr.14 | T/C | 外显子 Exonic | Scaffold 14-snap-gene-869.1 | 纤溶酶原激活蛋白抑制因子1 RNA结合蛋白 Plasminogen activator inhibitor 1 RNA-binding protein | 同义突变 Synonymous | 外显子4:c.T672C:p.D224D Exon4:c.T672C:p.D224D | |||
| 31 | SNP-14-87149383 | 0.4983 | Chr.14 | G/T | 外显子 Exonic | Scaffold 14-snap-gene-871.12 | 蛋白霜霉病抗性6 Protein downy mildew resistance 6 | 非同义突变 Nonsynonymous | 外显子3:c.G659T:p.S220I Exon3:c.G659T:p.S220I | |||
表4
8个核心位点Sanger测序的引物信息"
| 位点 Loci | 正向引物 Forward Primer (5'-3') | 反向引物 Reverse Primer (5'-3') | 退火温度 Tm (℃) | 产物 Product (bp) | SNP在产物上的位置 SNP location on the product (bp) |
|---|---|---|---|---|---|
| SNP-1-34038354 | CGTGTCACAACCTAGTTCCC | ACCAAGGACGCAGTTCTTC | 40.7 | 350 | 216 |
| SNP-1-110833857 | AGAGATTAAGATGTAACAACCAGT | CACTGTCCTCAGATAATTGATGTT | 36.7 | 425 | 274 |
| SNP-11-175529761 | AGGGGTAGTGTTTCTTGGATTTTC | CAGGTCATCAGCATGGAGTTG | 44.3 | 404 | 198 |
| SNP-14-86914708 | GGAATGAATTTAAACGTGATGGT | TTCTCTACTTCTCACTACATACTT | 38 | 434 | 273 |
| SNP-14-87149383 | TTGGCTCCGACATACCTAAGA | GCAGGCTCAACCACTTCAT | 47.8 | 383 | 182 |
| SNP-2-4697104 | GGACACCAGACAGAGGAATAATC | GTTATCCACAGCCCACTTCAG | 49.7 | 372 | 241 |
| SNP-5-175443498 | ATCACACTGTAGTAGCGGACAA | CACACGCCTCCACAATCTTC | 46.8 | 455 | 241 |
| SNP-9-23224047 | ACGGTGATGCTGTGTTCTT | TGCTTGGAATAATTGAATCCTGTG | 38.2 | 437 | 177 |
表5
8个核心SNP位点的Sanger测序验证结果"
| SNP位点 SNP loci | 总数量 Total No. | 验证数量 Verified | 验证率 Verification rate (%) | 基因型1 Genotype 1 | RNA- seq | Sanger | 基因型2 Genotype 2 | RNA- seq | Sanger | 基因型3 Genotype 3 | RNA- seq | Sanger |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNP-1-34038354 | 220 | 209 | 95.00 | TT | 71 | 66 | AT | 115 | 111 | AA | 34 | 32 |
| SNP-1-110833857 | 220 | 209 | 95.00 | GG | 27 | 27 | CG | 111 | 108 | CC | 82 | 77 |
| SNP-11-175529761 | 220 | 201 | 91.36 | GG | 68 | 64 | CG | 111 | 104 | CC | 41 | 33 |
| SNP-14-86914708 | 220 | 208 | 94.55 | TT | 43 | 41 | CT | 94 | 86 | CC | 83 | 81 |
| SNP-14-87149383 | 220 | 209 | 95.00 | GG | 60 | 60 | GT | 114 | 108 | TT | 46 | 41 |
| SNP-2-4697104 | 220 | 208 | 94.55 | TT | 82 | 79 | AT | 114 | 107 | AA | 24 | 23 |
| SNP-5-175443498 | 215 | 203 | 94.42 | TT | 36 | 32 | TG | 94 | 91 | GG | 85 | 80 |
| SNP-9-23224047 | 220 | 209 | 95.00 | TT | 76 | 73 | CT | 110 | 105 | CC | 34 | 31 |
| 合计Total | 1755 | 1662 | 94.70 | - | - | - | - | - | - | - | - | - |
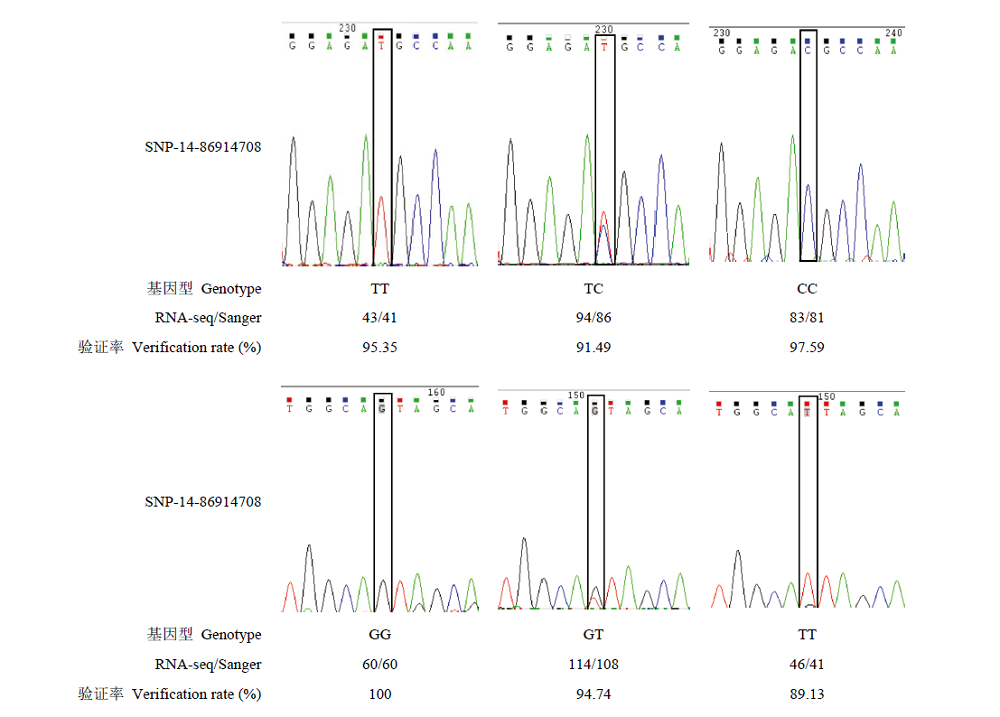
图2
部分核心SNP位点Sanger测序验证结果"

图3
8个亚群共计221个油茶无性系的分子指纹图谱"
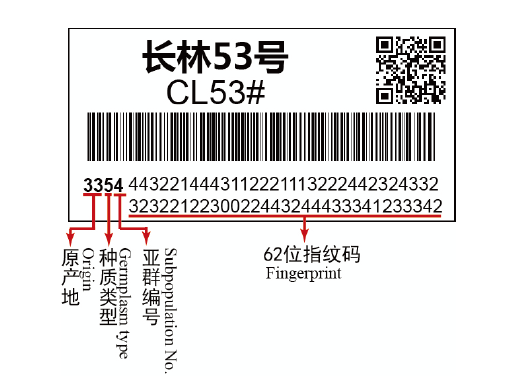
图4
油茶品种长林53号的分子身份证"

图5
221个油茶无性系的分子身份证"
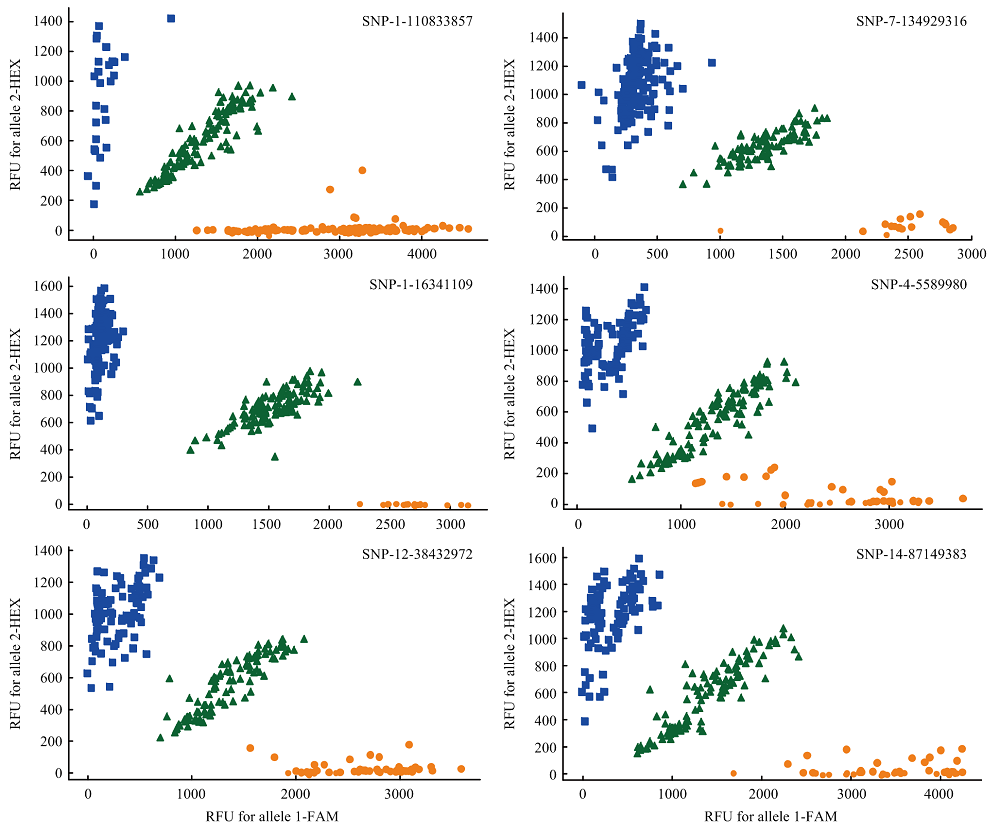
图6
部分核心SNP位点KASPar分析基因型结果"
| [1] | 庄瑞林. 中国油茶(第2版). 北京: 中国林业出版社, 2008. |
| ZHUANG R L. Oil-tea Camellia in China (2nd ed). Beijing: China Forestry Publishing House, 2008. (in Chinese) | |
| [2] |
LIN P, WANG K L, WANG Y P, HU Z K, YAN C, HUANG H, MA X J, CAO Y Q, LONG W, LIU W X, LI X L, FAN Z Q, LI J Y, YE N, REN H D, YAO X H, YIN H F. The genome of oil-Camellia and population genomics analysis provide insights into seed oil domestication. Genome Biology, 2022, 23(1): 14.
doi: 10.1186/s13059-021-02599-2 pmid: 35012630 |
| [3] | 姚小华, 王开良, 任华东, 林萍. 油茶资源与科学利用研究. 北京: 科学出版社, 2012. |
| YAO X H, WANG K L, REN H D, LIN P. The Research on Oil Camellia Resources and Its Scientific Utilization. Beijing: Science Press, 2012. (in Chinese) | |
| [4] | 林萍, 周长富, 姚小华, 曹永庆. 普通油茶两个Δ-12脂肪酸脱氢酶基因序列特征及表达模式研究. 林业科学研究, 2016, 29(5): 743-751. |
| LIN P, ZHOU C F, YAO X H, CAO Y Q. Sequence and expression characterization of two genes encoding Δ-12 fatty acid desaturases from Camellia oleifera. Forest Research, 2016, 29(5): 743-751. (in Chinese) | |
| [5] | 孙正文. 陆地棉种质资源SNP指纹图谱构建及重要农艺性状全基因组关联分析[D]. 保定: 河北农业大学, 2017. |
| SUN Z W. SNP fingerprint and genome-wide association studies of important agronomic traits for upland cotton[D]. Baoding: Agricultural University of Hebei, 2017. (in Chinese) | |
| [6] |
魏中艳, 李慧慧, 李骏, Gamar Y A, 马岩松, 邱丽娟. 应用SNP精准鉴定大豆种质及构建可扫描身份证. 作物学报, 2018, 44(3): 315-323.
doi: 10.3724/SP.J.1006.2018.00315 |
|
WEI Z Y, LI H H, LI J, GAMAR Y A, MA Y S, QIU L J. Accurate identification of varieties by nucleotide polymorphisms and establishment of scannable variety IDs for soybean germplasm. Acta Agronomica Sinica, 2018, 44(3): 315-323. (in Chinese)
doi: 10.3724/SP.J.1006.2018.00315 |
|
| [7] |
朱国忠, 张芳, 付洁, 李乐晨, 牛二利, 郭旺珍. 适于陆地棉品种身份鉴定的SNP核心位点筛选与评价. 作物学报, 2018, 44(11): 1631-1639.
doi: 10.3724/SP.J.1006.2018.01631 |
|
ZHU G Z, ZHANG F, FU J, LI L C, NIU E L, GUO W Z. Genome- wide screening and evaluation of SNP core loci for identification of upland cotton varieties. Acta Agronomica Sinica, 2018, 44(11): 1631-1639. (in Chinese)
doi: 10.3724/SP.J.1006.2018.01631 |
|
| [8] | 樊晓静, 于文涛, 蔡春平, 林浥, 王泽涵, 房婉萍, 张见明, 叶乃兴. 利用SNP标记构建茶树品种资源分子身份证. 中国农业科学, 2021, 54(8): 1751-1772. |
| FAN X J, YU W T, CAI C P, LIN Y, WANG Z H, FANG W P, ZHANG J M, YE N X. Construction of molecular ID for tea cultivars by using of single-nucleotide polymorphism (SNP) markers. Scientia Agricultura Sinica, 2021, 54(8): 1751-1772. (in Chinese) | |
| [9] | 王琰琰. 雪茄烟种质资源SNP指纹图谱构建及群体遗传分析[D]. 北京: 中国农业科学院, 2021. |
| WANG Y Y. Construction of a SNP fingerprinting database and population genetic analysis of cigar tobacco germplasm resources in China[D]. Beijing: Chinese Academy of Agricultural Sciences, 2021. (in Chinese) | |
| [10] |
陈小红, 林元香, 王倩, 丁敏, 王海岗, 陈凌, 高志军, 王瑞云, 乔治军. 基于高基元SSR构建黍稷种质资源的分子身份证. 作物学报, 2022, 48(4): 908-919.
doi: 10.3724/SP.J.1006.2022.14034 |
|
CHEN X H, LIN Y X, WANG Q, DING M, WANG H G, CHEN L, GAO Z J, WANG R Y, QIAO Z J. Development of DNA molecular ID card in hog millet germplasm based on high motif SSR. Acta Agronomica Sinica, 2022, 48(4): 908-919. (in Chinese)
doi: 10.3724/SP.J.1006.2022.14034 |
|
| [11] | 陈永忠, 张智俊, 谭晓风. 油茶优良无性系的RAPD分子鉴别. 中南林业科技大学学报, 2005, 25(4): 40-45. |
| CHEN Y Z, ZHANG Z J, TAN X F. Identification of oil tea (Camellia oleifera) superior clones by RAPD molecular marker. Journal of Central South Forestry University, 2005, 25(4): 40-45. (in Chinese) | |
| [12] | 温强, 雷小林, 叶金山, 江梅, 左继林, 黄丽莉, 江香梅, 徐林初. 油茶高产无性系的ISSR分子鉴别. 中南林业科技大学学报(自然科学版), 2008, 28(1): 39-43. |
| WEN Q, LEI X L, YE J S, JIANG M, ZUO J L, HUANG L L, JIANG X M, XU L C. Identification of Camellia oleifera superior clones by ISSR molecular markers. Journal of Central South University of Forestry and Technology (Natural Science Edition), 2008, 28(1): 39-43. (in Chinese) | |
| [13] | 范海艳, 曹福祥, 彭继庆, 龙绛雪, 邓明, 司书斌. 博白大果油茶ISSR-PCR反应体系的建立与优化. 中南林业科技大学学报(自然科学版), 2011, 31(4):97-103. |
| FAN H Y, CAO F X, PENG J Q, LONG J X, DENG M, SI S B. Establishment and optimization of ISSR-PCR reaction system of Camellia gigantocarpa. Journal of Central South University of Forestry and Technology (Natural Science Edition), 2011, 31(4): 97-103. (in Chinese) | |
| [14] | 代惠萍, 赵桦, 吴三桥, 孙志峰, 魏安智. 秦巴山区油茶品种遗传多样性的ISSR分析. 西北林学院学报, 2014, 29(2): 107-111. |
| DAI H P, ZHAO H, WU S Q, SUN Z F, WEI A Z. ISSR analysis of genetic diversity of Camellia oleifera in Qinba mountains. Journal of Northwest Forestry University, 2014, 29(2): 107-111. (in Chinese) | |
| [15] | 曹志华, 束庆龙, 曹翠萍, FINKELDEY R. 安徽主要油茶良种的抗炭疽病鉴定和AFLP遗传多样性分析. 全国油茶技术协作组油茶学术交流会论文集. 杭州: 浙江科学技术出版社, 2013: 54-60. |
| CAO Z H, SHU Q L, CAO C P, FINKELDEY R. Identification of resistance to anthracnose and AFLP genetic diversity analysis of major Camellia oleifera cultivars in Anhui province. Oil tea academic exchange meeting of national oil tea technology cooperation group. Hangzhou: Zhejiang Science and Technology Press, 2013: 54-60. (in Chinese) | |
| [16] | 林萍, 姚小华, 王开良, 郑婷婷, 滕建华. 油茶长林系列优良无性系的SRAP分子鉴别及遗传分析. 农业生物技术学报, 2010, 18(2): 272-279. |
| LIN P, YAO X H, WANG K L, ZHENG T T, TENG J H. Identification and genetic analysis of Camellia oleifera Changlin series superior clones by SRAP molecular marker. Journal of Agricultural Biotechnology, 2010, 18(2): 272-279. (in Chinese) | |
| [17] | 郑婷婷. 油茶种质资源遗传多样性分析与无性系鉴别[D]. 重庆: 西南大学, 2010. |
| ZHENG T T. Analysis of genetic diversity of Camellia oleifera and clone identification[D]. Chongqing: Southwest University, 2010. (in Chinese) | |
| [18] | 李海波, 丁红梅, 陈友吾, 徐梁, 李楠, 胡传久. 12个油茶品种的SSR特征指纹鉴别. 中国粮油学报, 2017, 32(10): 171-178. |
| LI H B, DING H M, CHEN Y W, XU L, LI N, HU C J. Identification of 12 superior cultivars of Camellia oleifera by using simple sequence repeat feature indexes. Journal of the Chinese Cereals and Oils Association, 2017, 32(10): 171-178. (in Chinese) | |
| [19] | HUANG X M, CHEN J M, YANG X Q, DUAN S H, LONG C, GE G, RONG J. Low genetic differentiation among altitudes in wild Camellia oleifera, a subtropical evergreen hexaploid plant. Tree Genetics & Genomes, 2018, 14(2): 1-12. |
| [20] |
LIN P, YIN H F, YAN C, YAO X H, WANG K L. Association genetics identifies single nucleotide polymorphisms related to kernel oil content and quality in Camellia oleifera. Journal of Agricultural and Food Chemistry, 2019, 67(9): 2547-2562.
doi: 10.1021/acs.jafc.8b03399 |
| [21] |
CUI X Y, LI C H, QIN S Y, HUANG Z B, GAN B, JIANG Z W, HUANG X M, YANG X Q, LI Q, XIANG X G, CHEN J K, ZHAO Y, RONG J. High-throughput sequencing-based microsatellite genotyping for polyploids to resolve allele dosage uncertainty and improve analyses of genetic diversity, structure and differentiation: A case study of the hexaploid Camellia oleifera. Molecular Ecology Resources, 2022, 22(1): 199-211.
doi: 10.1111/1755-0998.13469 |
| [22] |
SHEN T F, HUANG B, XU M, ZHOU P Y, NI Z X, GONG C, WEN Q, CAO F L, XU L. The reference genome of Camellia chekiangoleosa provides insights into camellia evolution and tea oil biosynthesis. Horticulture Research, 2022, 9: uhab083.
doi: 10.1093/hr/uhab083 |
| [23] |
GONG W F, XIAO S X, WANG L K, LIAO Z Y, CHANG Y H, MO W J, HU G X, LI W Y, ZHAO G, ZHU H G, HU X M, JI K, XIANG X F, SONG Q L, YUAN D Y, JIN S X, ZHANG L. Chromosome-level genome of Camellia lanceoleosa provides a valuable resource for understanding genome evolution and self-incompatibility. The Plant Journal, 2022, 110(3): 881-898.
doi: 10.1111/tpj.15739 |
| [24] |
DU H S, YANG J J, CHEN B, ZHANG X F, ZHANG J, YANG K, GENG S S, WEN C L. Target sequencing reveals genetic diversity, population structure, core-SNP markers, and fruit shape-associated loci in pepper varieties. BMC Plant Biology, 2019, 19(1): 578.
doi: 10.1186/s12870-019-2122-2 pmid: 31870303 |
| [25] | 李志远, 于海龙, 方智远, 杨丽梅, 刘玉梅, 庄木, 吕红豪, 张扬勇. 甘蓝SNP标记开发及主要品种的DNA指纹图谱构建. 中国农业科学, 2018, 51(14): 2771-2788. |
| LI Z Y, YU H L, FANG Z Y, YANG L M, LIU Y M, ZHUANG M, LÜ H H, ZHANG Y Y. Development of SNP markers in cabbage and construction of DNA fingerprinting of main varieties. Scientia Agricultura Sinica, 2018, 51(14): 2771-2788. (in Chinese) | |
| [26] |
魏庆镇, 王五宏, 胡天华, 胡海娇, 汪精磊, 包崇来. 浙茄类型茄子品种DNA指纹图谱构建. 浙江农业学报, 2019, 31(11): 1863-1870.
doi: 10.3969/j.issn.1004-1524.2019.11.12 |
|
WEI Q Z, WANG W H, HU T H, HU H J, WANG J L, BAO C L. Construction of DNA fingerprinting of Zhejiang eggplant varieties. Acta Agriculturae Zhejiangensis, 2019, 31(11): 1863-1870. (in Chinese)
doi: 10.3969/j.issn.1004-1524.2019.11.12 |
|
| [27] | 李梓榕, 袁雄, 陈叶, 郑兴飞, 胡中立, 李兰芝. 基于全基因组SNP高效鉴定水稻种质资源并构建指纹图谱. 分子植物育种, 2020, 18(18): 6050-6057. |
| LI Z R, YUAN X, CHEN Y, ZHENG X F, HU Z L, LI L Z. Effective identification for varieties by genome-wide SNPs and establishment of fingerprint for rice germplasm. Molecular Plant Breeding, 2020, 18(18): 6050-6057. (in Chinese) | |
| [28] |
刘丽华, 刘阳娜, 张明明, 李宏博, 庞斌双, 赵昌平. 我国75份小麦品种SNP和SSR指纹图谱构建与比较分析. 中国农业科技导报, 2020, 22(5): 15-23.
doi: 10.13304/j.nykjdb.2019.1023 |
|
LIU L H, LIU Y N, ZHANG M M, LI H B, PANG B S, ZHAO C P. Construction and comparative analysis of SNP and SSR fingerprints of 75 wheat cultivars in China. Journal of Agricultural Science and Technology, 2020, 22(5): 15-23. (in Chinese)
doi: 10.13304/j.nykjdb.2019.1023 |
|
| [29] | 张昆鹏. 利用SNP标记构建油菜品种指纹图谱及定位下卷叶性状基因的研究[D]. 南京: 南京农业大学, 2013. |
| ZHANG K P. Studies on rapeseed variety fingerprints and mapping of gene of the down-curly leaf by use of SNP markers in Brassica napus L.[D]. Nanjing: Nanjing Agricultural University, 2013. (in Chinese) | |
| [30] | 顾炳朝, 岳绪国, 杨军, 巫章平, 曹小宏, 朱建飞. 油菜品种镇油6号的指纹图谱分析. 江苏农业科学, 2015, 43(1): 87-89. |
| GU B C, YUE X G, YANG J, WU Z P, CAO X H, ZHU J F. Fingerprint analysis of Rape variety ‘Zhenyou No. 6’. Jiangsu Agricultural Sciences, 2015, 43(1): 87-89. (in Chinese) | |
| [31] | 匡猛. 基于SSR与SNP标记的棉花品种鉴定与指纹库构建研究[D]. 保定: 河北农业大学, 2016. |
| KUANG M. Cotton variety identification and construction of DNA fingerprinting database based on SSR and SNP markers[D]. Baoding: Agricultural University of Hebei, 2016. (in Chinese) | |
| [32] |
李乐晨, 朱国忠, 苏秀娟, 郭旺珍. 适于海岛棉指纹图谱构建的SNP核心位点筛选与评价. 作物学报, 2019, 45(5): 647-655.
doi: 10.3724/SP.J.1006.2019.84123 |
|
LI L C, ZHU G Z, SU X J, GUO W Z. Genome-wide screening and evaluation of SNP core loci for fingerprinting construction of cotton accessions (G. barbadense). Acta Agronomica Sinica, 2019, 45(5): 647-655. (in Chinese)
doi: 10.3724/SP.J.1006.2019.84123 |
|
| [33] | 乔大河, 郭燕, 杨春, 李燕, 陈娟, 陈正武. 贵州省主要栽培茶树品种指纹图谱构建与遗传结构分析. 植物遗传资源学报, 2019, 20(2): 412-425. |
| QIAO D H, GUO Y, YANG C, LI Y, CHEN J, CHEN Z W. Fingerprinting construction and genetic structure analysis of the main cultivated tea varieties in Guizhou province. Journal of Plant Genetic Resources, 2019, 20(2): 412-425. (in Chinese) | |
| [34] | 李娟, 林建勇, 欧汉彪, 刘雄盛, 姜英, 梁瑞龙. 基于SLAF-seq技术的闽楠SNP标记开发及遗传多样性分析. 分子植物育种, 2021, 19(13): 4517-4524. |
| LI J, LIN J Y, OU H B, LIU X S, JIANG Y, LIANG R L. Marker development and analysis of genetic diversity of phoebe bournei germplasms using SLAF-seq technology. Molecular Plant Breeding, 2021, 19(13): 4517-4524. (in Chinese) | |
| [35] | 姚小华. 中国油茶品种志. 北京: 中国林业出版社, 2016: 39-59. |
| YAO X H. Oil-tea Camellia cultivars in China. Beijing: China Forestry Press, 2016: 39-59. (in Chinese) | |
| [36] | VAN DER-AUWERA G A, CARNEIRO M O, HARTL C, POPLIN R, DEL ANGEL G, LEVY-MOONSHINE A, JORDAN T, SHAKIR K, ROAZEN D, THIBAULT J, BANKS E, GARIMELLA K V, ALTSHULER D, GABRIEL S, DEPRISTO M A. From FastQ data to high confidence variant calls: The genome analysis toolkit best practices pipeline. Current Protocols in Bioinformatics, 2013, 43(1110): 11.10. 1-11.10.33. |
| [37] |
PFEIFER B, WITTELSBÜRGER U, RAMOS-ONSINS S E, LERCHER M J. PopGenome: An efficient swiss army knife for population genomic analyses in R. Molecular Biology and Evolution, 2014, 31(7): 1929-1936.
doi: 10.1093/molbev/msu136 pmid: 24739305 |
| [38] |
WRIGHT S. The genetical structure of populations. Annals of Eugenics, 1951, 15(4): 323-354.
doi: 10.1111/j.1469-1809.1949.tb02451.x pmid: 24540312 |
| [39] |
SU T B, LI P R, YANG J J, SUI G L, YU Y J, ZHANG D S, ZHAO X Y, WAGN W H, WEN C L, YU S C, ZHANG F L. Development of cost-effective single nucleotide polymorphism marker assays for genetic diversity analysis in Brassica rapa. Molecular Breeding, 2018, 38(4): 1-13.
doi: 10.1007/s11032-017-0759-9 |
| [40] | 张成才, 刘园, 姜燕华, 吴立赟, 王丽鸳, 韦康, 成浩. SSR标记鉴定浙江省主要无性系茶树品种的研究. 植物遗传资源学报, 2014, 15(5): 926-931. |
| ZHANG C C, LIU Y, JIANG Y H, WU L Y, WANG L Y, WEI K, CHENG H. Application of SSR markers in cultivar identification of clonal tea plant in Zhejiang province, China. Journal of Plant Genetic Resources, 2014, 15(5): 926-931. (in Chinese) | |
| [41] | 徐云碧, 王冰冰, 张健, 张嘉楠, 李建生. 应用分子标记技术改进作物品种保护和监管. 作物学报, 2022, 48(8): 1853-1870. |
| XU Y B, WANG B B, ZHANG J, ZHANG J N, LI J S. Enhancement of plant variety protection and regulation using molecular marker technology. Acta Agronomica Sinica, 2022, 48(8): 1853-1870. (in Chinese) | |
| [42] |
BENTLEY N, GRAUKE L J, KLEIN P. Genotyping by sequencing (GBS) and SNP marker analysis of diverse accessions of pecan (Carya illinoinensis). Tree Genetics and Genomes, 2019, 15(1): 1-17.
doi: 10.1007/s11295-018-1309-2 |
| [43] |
COLONNA V, D'AGOSTINO N, GARRISON E, ALBRECHTSEN A, MEISNER J, FACCHIANO A, CARDI T, TRIPODI P. Genomic diversity and novel genome-wide association with fruit morphology in Capsicum, from 746K polymorphic sites. Scientific Reports, 2019, 9: 10067.
doi: 10.1038/s41598-019-46136-5 pmid: 31296904 |
| [44] |
WRIGHT S. The interpretation of population structure by F-statistics with special regard to systems of mating. Evolution, 1965, 19(3): 395-420.
doi: 10.2307/2406450 |
| [45] | 黄勇. 小果油茶与普通油茶居群遗传结构及种间杂交渐渗. 应用生态学报, 2013, 24(8): 2345-2352. |
| HUANG Y. Population genetic structure and interspecific introgressive hybridization between Camellia meiocarpa and C. oleifera. Chinese Journal of Applied Ecology, 2013, 24(8): 2345-2352. (in Chinese) | |
| [46] | 陈昌文, 曹珂, 王力荣, 朱更瑞, 方伟超. 中国桃主要品种资源及其野生近缘种的分子身份证构建. 中国农业科学, 2011, 44(10): 2081-2093. |
| CHEN C W, CAO K, WANG L R, ZHU G R, FANG W C. Molecular ID establishment of main China peach varieties and peach related species. Scientia Agricultura Sinica, 2011, 44(10): 2081-2093. (in Chinese) | |
| [47] | 冉昆, 隋静, 王宏伟, 魏树伟, 张勇, 董冉, 董肖昌, 王少敏. 利用SSR荧光标记构建山东地方梨种质资源分子身份证. 果树学报, 2018, 35(S1): 71-78. |
| RAN K, SUI J, WANG H W, WEI S W, ZHANG Y, DONG R, DONG X C, WANG S M. Using the fluorescent labeled SSR markers to establish the molecular ID of pear germplasm resources in Shandong. Journal of Fruit Science, 2018, 35(S1): 71-78. (in Chinese) | |
| [48] |
CHEN L N, MA Q G, CHEN Y K, WANG B Q, PEI D. Identification of major walnut cultivars grown in China based on nut phenotypes and SSR markers. Scientia Horticulturae, 2014, 168: 240-248.
doi: 10.1016/j.scienta.2014.02.004 |
| [1] | 曹海顺, 周东源, 王瑞, 施招婉, 吴廷全, 张长远. 弱光胁迫短下胚轴黄瓜种质鉴定及其遗传位点挖掘[J]. 中国农业科学, 2026, 59(6): 1286-1301. |
| [2] | 苏晓梅, 杨宗辉, 刘淑梅, 张宗杰, 吕宏君, 侯丽霞. 番茄品种KASP标记鉴定技术体系的构建与应用[J]. 中国农业科学, 2025, 58(22): 4746-4756. |
| [3] | 刘宏祥, 张雪萍, 王逸飞, 王志成, 顾昊天, 宋卫涛, 陶志云, 徐文娟, 章双杰, 卢立志, 李慧芳, 朱春红. 金定鸭产蛋数性状的全基因组关联研究[J]. 中国农业科学, 2025, 58(15): 3145-3158. |
| [4] | 张茗起, 王蕊, 张春宵, 孙擘, 任洁, 李淑芳, 王璐, 朱少喜, 张江斌, 施昕晨, 王海杰, 张云龙, 田红丽, 赵怡锟, 匡猛, 王元东, 易红梅, 李晓辉, 王凤格. 吉林省玉米种质资源SSR和SNP分子身份证的构建及应用[J]. 中国农业科学, 2024, 57(2): 236-249. |
| [5] | 苏国钊, 李嫒嫒, 刘中华, 陈宇华, 张秀杰, 马莹雪, 杨旭红, 邓超, 徐振江. 苦瓜品种SSR分子标记鉴定技术体系构建与应用[J]. 中国农业科学, 2024, 57(11): 2227-2242. |
| [6] | 孙艳发, 吴琼, 林如龙, 陈红萍, 甘秋云, 沈玥, 王亚茹, 薛鹏飞, 陈飞帆, 刘健涛, 周陈鑫, 兰诗诗, 潘浩哲, 邓凡, 岳稳, 江宵兵, 李焰. 龙岩山麻鸭蛋品质性状的全基因组关联研究[J]. 中国农业科学, 2023, 56(3): 572-586. |
| [7] | 薛亚鹏, 丁艺冰, 王宇卓, 王晓丹, 曹晓宁, SANTRA Dipak K, 陈凌, 乔治军, 王瑞云. 基于荧光SSR构建中国糜子核心种质DNA分子身份证[J]. 中国农业科学, 2023, 56(12): 2249-2261. |
| [8] | 赵春芳,赵庆勇,吕远大,陈涛,姚姝,赵凌,周丽慧,梁文化,朱镇,王才林,张亚东. 半糯粳稻品种核心标记的筛选及DNA指纹图谱的构建[J]. 中国农业科学, 2022, 55(23): 4567-4582. |
| [9] | 李晓川,王朝海,周平,马维,吴瑞,宋治豪,梅艳. 马铃薯品种(系)田间晚疫病抗性评价和全基因组遗传多样性分析[J]. 中国农业科学, 2022, 55(18): 3484-3500. |
| [10] | 樊晓静, 于文涛, 蔡春平, 林浥, 王泽涵, 房婉萍, 张见明, 叶乃兴. 利用SNP标记构建茶树品种资源分子身份证[J]. 中国农业科学, 2021, 54(8): 1751-1760. |
| [11] | 张鹏飞,史良玉,刘家鑫,李洋,吴成斌,王立贤,赵福平. 畜禽全基因组长纯合片段检测的研究进展[J]. 中国农业科学, 2021, 54(24): 5316-5326. |
| [12] | 刘强,刘纪伟,田恬,严薇,刘兵,赵思琪,胡秋辉,丁超. 高温胁迫下糙米短期储藏气味指纹图谱变化规律的动态分析[J]. 中国农业科学, 2021, 54(2): 379-391. |
| [13] | 王富强,张建,温常龙,樊秀彩,张颖,孙磊,刘崇怀,姜建福. 基于KASP标记的葡萄品种鉴定[J]. 中国农业科学, 2021, 54(13): 2830-2842. |
| [14] | 彭蕴,雷天刚,邹修平,张靖芸,张庆雯,姚家欢,何永睿,李强,陈善春. 柑橘溃疡病抗性SNP验证及其相关钙依赖性蛋白激酶基因诱导表达[J]. 中国农业科学, 2020, 53(9): 1820-1829. |
| [15] | 徐云碧,杨泉女,郑洪建,许彦芬,桑志勤,郭子锋,彭海,张丛,蓝昊发,王蕴波,吴坤生,陶家军,张嘉楠. 靶向测序基因型检测(GBTS)技术及其应用[J]. 中国农业科学, 2020, 53(15): 2983-3004. |
|
||